Архітектура Kubernetes — анатомія кластера
Архітектура Kubernetes — анатомія кластера
Від одного демона до розподіленої системи
Коли ви працювали з Docker, вся взаємодія зводилась до однієї простої схеми: ви виконували docker run, Docker-демон (dockerd) на вашому сервері отримував команду, завантажував образ і запускав контейнер. Один хост — один демон — одна точка управління. Усе прозоро і зрозуміло.
Kubernetes принципово інший. Він не є одним процесом і не працює на одній машині. Kubernetes — це розподілена система: сукупність кількох взаємодіючих компонентів, розгорнутих на різних машинах, які разом утворюють єдиний керований простір.
Розуміння цієї архітектури є необхідною умовою для ефективної роботи з Kubernetes. Без нього навіть прості помилки стають незрозумілими, а усунення несправностей перетворюється на вгадування. У цій статті ми пройдемо анатомію кластера від зовнішнього вигляду до внутрішніх механізмів — крок за кроком, без пропусків.
Кластер — основна одиниця Kubernetes
Перша і найважливіша концепція, яку необхідно засвоїти: у Kubernetes ви не працюєте з окремими серверами. Ви працюєте з кластером.
Кластер (cluster) — це сукупність машин (фізичних або віртуальних серверів), обʼєднаних під управлінням Kubernetes і представлених як єдиний обчислювальний ресурс. З точки зору оператора, кластер — це «один великий комп'ютер»: ви описуєте, що хочете запустити і скільки ресурсів це потребує, а Kubernetes сам вирішує, де і як це розмістити.
Кожна машина, що входить до кластера, називається вузлом (node). Вузли бувають двох типів — але про це трохи пізніше. Спочатку познайомимось з інструментом, яким оператор взаємодіє з кластером.
kubectl — інструмент оператора
kubectl (вимовляється «кюб-контрол» або «кюбектл») — це командний рядковий інтерфейс (CLI) для взаємодії з Kubernetes-кластером. Якщо проводити паралель із Docker, kubectl відіграє ту саму роль, що і команда docker — він формує запити до API кластера та відображає відповіді.
Аналогія точна, але не повна: docker CLI спілкується з демоном на тому ж хості, тоді як kubectl може взаємодіяти з кластером з будь-якої машини — з вашого ноутбука, з CI/CD-системи, з іншого сервера — через захищене HTTPS-підключення.
Загальна анатомія команди kubectl:
kubectl [дієслово] [тип-ресурсу] [імʼя] [прапорці]
| Частина | Опис | Приклад |
|---|---|---|
дієслово | Що зробити | get, apply, delete, describe |
тип-ресурсу | З яким об'єктом | node, pod, deployment, service |
імʼя | Конкретний екземпляр (необов'язково) | my-app-pod |
прапорці | Додаткові параметри | -n production, -o yaml |
Перші команди, які ви виконаєте у будь-якому кластері:
# Переглянути вузли кластера та їхній стан
kubectl get nodes
# Переглянути поточний контекст (до якого кластера підключено)
kubectl config current-context
kubectl зберігає налаштування підключення (адреси кластерів, credentials, поточний контекст) у файлі ~/.kube/config. Завдяки цьому ви можете перемикатися між кластерами однією командою: kubectl config use-context <назва-контексту>.Тепер, коли ми знаємо інструмент оператора, розглянемо архітектуру того, з чим цей інструмент взаємодіє.
Два типи вузлів: управління та виконання
Як зазначалось вище, кожна машина у кластері — це вузол. Але не всі вузли однакові: вони поділяються на два принципово різні типи залежно від ролі, яку виконують.
Control Plane (площина управління) — це «мозок» кластера. Вузли цього типу не запускають ваші застосунки. Їхнє завдання — зберігати стан усієї системи, приймати рішення (що запустити, де розмістити, як реагувати на збої) та автоматично підтримувати бажаний стан. У невеликих кластерах control plane розгортається на одному вузлі; у production — зазвичай на трьох, для відмовостійкості.
Worker Nodes (робочі вузли) — це «м'язи» кластера. Саме тут виконуються ваші застосунки. Кожен worker-вузол отримує інструкції від control plane і запускає контейнери відповідно до цих інструкцій. Кількість worker-вузлів визначає обчислювальну потужність кластера і може змінюватись динамічно — вузли можна додавати або видаляти без зупинки системи.
Зверніть увагу на принципову різницю в порівнянні з Docker Compose: там усе виконувалось на одній машині. Тут «управління» і «виконання» фізично розділені.
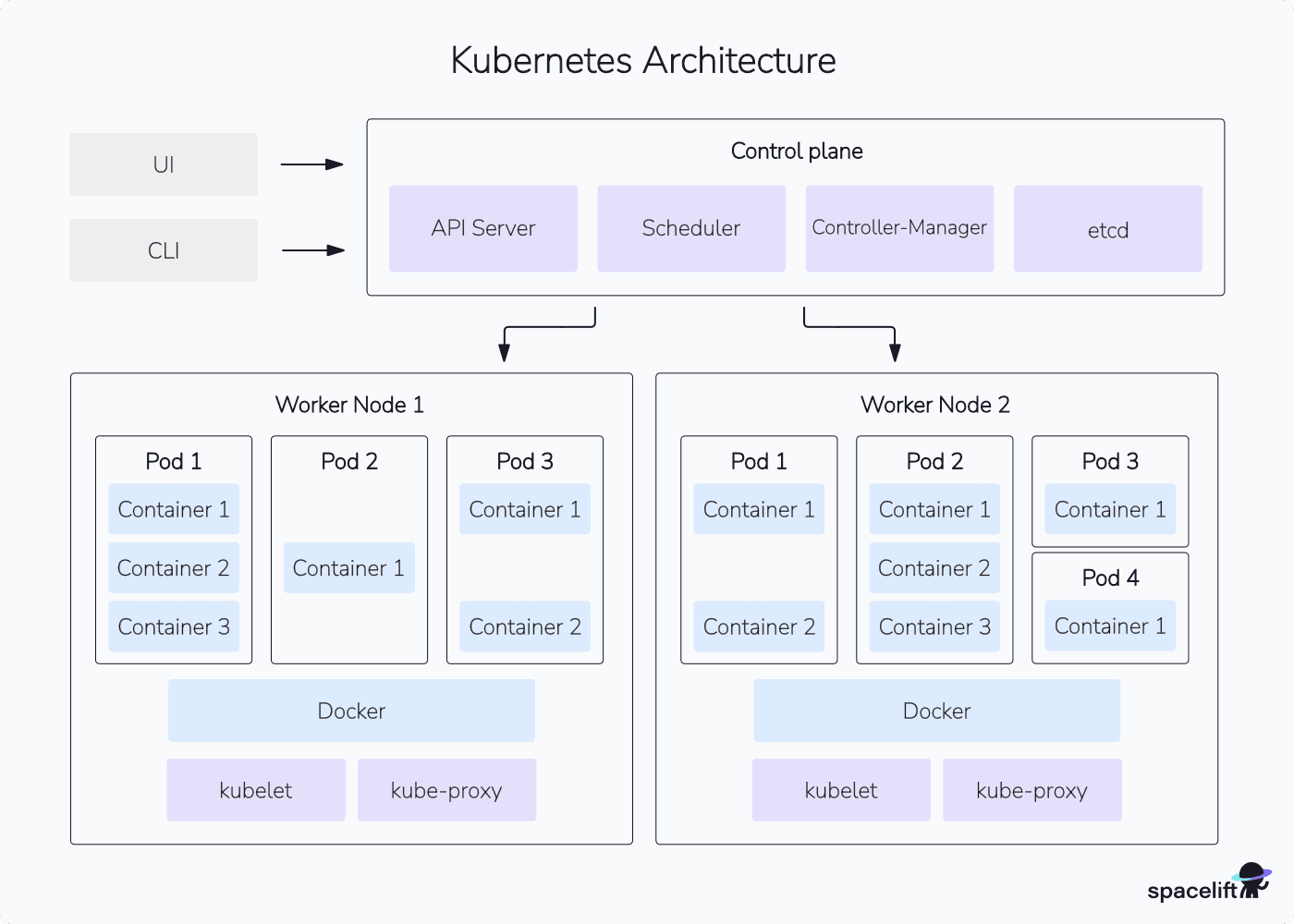
Зі схеми видно два потоки комунікації:
- Оператор → Control Plane: ваші
kubectl-команди надходять до control plane через HTTPS. - Control Plane ↔ Worker Nodes: control plane надсилає інструкції вузлам (що запускати), а вузли повертають актуальний статус (що реально виконується).
Ніколи не навпаки: оператор ніколи не спілкується з worker-вузлами напряму. Вся взаємодія відбувається через control plane.
Що таке Pod — базова одиниця виконання
Перш ніж розглядати компоненти вузлів детально, необхідно ввести одне ключове поняття, яке з'являтиметься у кожному наступному розділі.
Pod (від англ. «стручок») — це найменша розгортана одиниця у Kubernetes. Не контейнер, а саме Pod. Розуміння цього є принципово важливим для тих, хто приходить із Docker.
У Docker мінімальна одиниця — це контейнер. У Kubernetes — Pod, який є обгорткою над одним або кількома контейнерами. Pod гарантує, що всі контейнери всередині нього:
- Запускаються і зупиняються разом
- Знаходяться на одному вузлі
- Мають спільну мережу (один IP на Pod)
- Можуть мати спільні volumes (файли)
Аналогія: якщо Docker-контейнер — це окремий процес в ізольованому середовищі, то Pod — це «мінімальна логічна одиниця вашого застосунку», яку Kubernetes розміщує, масштабує та перезапускає як ціле.
Компоненти Control Plane
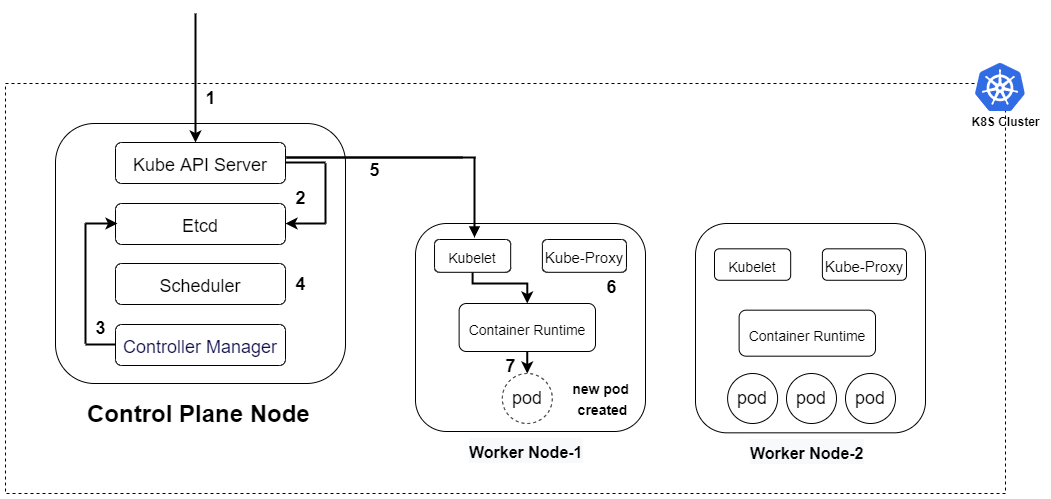
Control plane складається з чотирьох основних процесів. Кожен з них має чітко визначену відповідальність — жоден не виконує «все поспіль». Саме така модульність і дозволяє системі бути відмовостійкою та розширюваною.
kube-apiserver — єдина точка входу
kube-apiserver — це HTTP-сервер, через який проходять абсолютно всі операції у кластері. Ваш kubectl, внутрішні компоненти Kubernetes, зовнішні інструменти — всі вони звертаються виключно до API-сервера. Ніхто не спілкується з etcd або планувальником напряму.
kube-apiserver — це dockerd, але для цілого кластера. Так само, як docker CLI спілкується з dockerd через Unix-socket, kubectl спілкується з kube-apiserver через захищений HTTPS-канал.Потік обробки запиту
Кожен запит до API-сервера проходить через кілька етапів обробки. Розглянемо детально на прикладі команди kubectl get pods:
Етапи обробки запиту:
kubectl звертається до сервера, він автоматично пред'являє цей документ. Якщо паспорт недійсний або його немає — сервер навіть не почне розмову.LimitRanger перевіряє, чи не перевищує Pod ліміти ресурсів namespace. Це працює як автокорекція у смартфоні: якщо ви забули вказати важливий параметр, Admission Controller може підставити значення за замовчуванням ще до того, як дані потраплять у базу.etcd. Для запитів на читання — отримання даних з etcd.Приклад: створення Deployment
Тепер розглянемо складніший сценарій — kubectl apply -f deployment.yaml:
Ключові моменти:
- Admission Controllers можуть змінювати об'єкт перед збереженням (наприклад, додавати default значення)
- etcd зберігає об'єкт і повертає номер ревізії
- Watchers (scheduler, controller-manager) отримують подію про новий об'єкт через механізм watch
Watch API — механізм реального часу
API-сервер підтримує watch API — механізм, який дозволяє компонентам отримувати події про зміни у реальному часі, без постійного опитування (polling).
# Приклад watch-запиту
kubectl get pods --watch
Під капотом це HTTP-запит з параметром ?watch=true, який залишається відкритим, і API-сервер надсилає події через цей канал:
{"type": "ADDED", "object": {"kind": "Pod", "metadata": {"name": "nginx-1"}}}
{"type": "MODIFIED", "object": {"kind": "Pod", "metadata": {"name": "nginx-1"}, "status": {"phase": "Running"}}}
{"type": "DELETED", "object": {"kind": "Pod", "metadata": {"name": "nginx-1"}}}
Саме завдяки watch API scheduler дізнається про нові Pod, а controller-manager — про зміни у Deployment.
Stateless природа API-сервера
API-сервер є stateless (без внутрішнього стану): він не запам'ятовує нічого між запитами. Весь стан кластера живе у etcd. Завдяки цьому можна запускати кілька екземплярів API-сервера паралельно для відмовостійкості — всі вони читають і пишуть до одного etcd.
Якщо один екземпляр API-сервера падає — Load Balancer перенаправляє трафік на інші. Жоден стан не втрачається, бо все зберігається у etcd.
etcd — розподілена база даних стану
etcd (вимовляється «ет-сі-ді») — це розподілене сховище типу «ключ-значення», яке є єдиним джерелом правди для всього кластера. Тут зберігається все: поточний стан Podʼів, конфігурації, секрети, інформація про вузли, права доступу.
Назва «etcd» походить від Unix-конвенції: конфігурації традиційно зберігаються у директорії /etc, а суфікс -d означає «distributed» (розподілений).
etcd — найкритичніший компонент кластера. Якщо etcd повністю втрачає дані — кластер втрачає стан: Kubernetes вже не знає, які Podʼи мали бути запущені, які Deployment існували, які секрети були збережені. Відновлення можливе лише з резервної копії. У production etcd обовʼязково розгортається у кластері з трьох вузлів та має регулярні резервні копії.Структура даних у etcd
etcd зберігає всі об'єкти Kubernetes у ієрархічній структурі ключів. Кожен об'єкт має унікальний шлях:
/registry/
├── pods/
│ ├── default/
│ │ ├── nginx-deployment-7d6b8c9f4d-8xk2p
│ │ ├── nginx-deployment-7d6b8c9f4d-m5n7q
│ │ └── nginx-deployment-7d6b8c9f4d-z9w3r
│ └── kube-system/
│ ├── coredns-7db6d8ff4d-8xk2p
│ └── kube-apiserver-minikube
├── deployments/
│ └── default/
│ └── nginx-deployment
├── services/
│ └── default/
│ └── kubernetes
├── secrets/
│ └── default/
│ └── default-token-xxxxx
└── configmaps/
└── configmaps/
└── kube-system/
└── kubeadm-config
Кожен ключ містить повну специфікацію об'єкта у JSON-форматі. Наприклад, /registry/pods/default/nginx-deployment-7d6b8c9f4d-8xk2p містить:
{
"kind": "Pod",
"apiVersion": "v1",
"metadata": {
"name": "nginx-deployment-7d6b8c9f4d-8xk2p",
"namespace": "default",
"uid": "a3f8c9d1-2e45-4b6c-8d7e-9f0a1b2c3d4e",
"resourceVersion": "12345"
},
"spec": { ... },
"status": { ... }
}
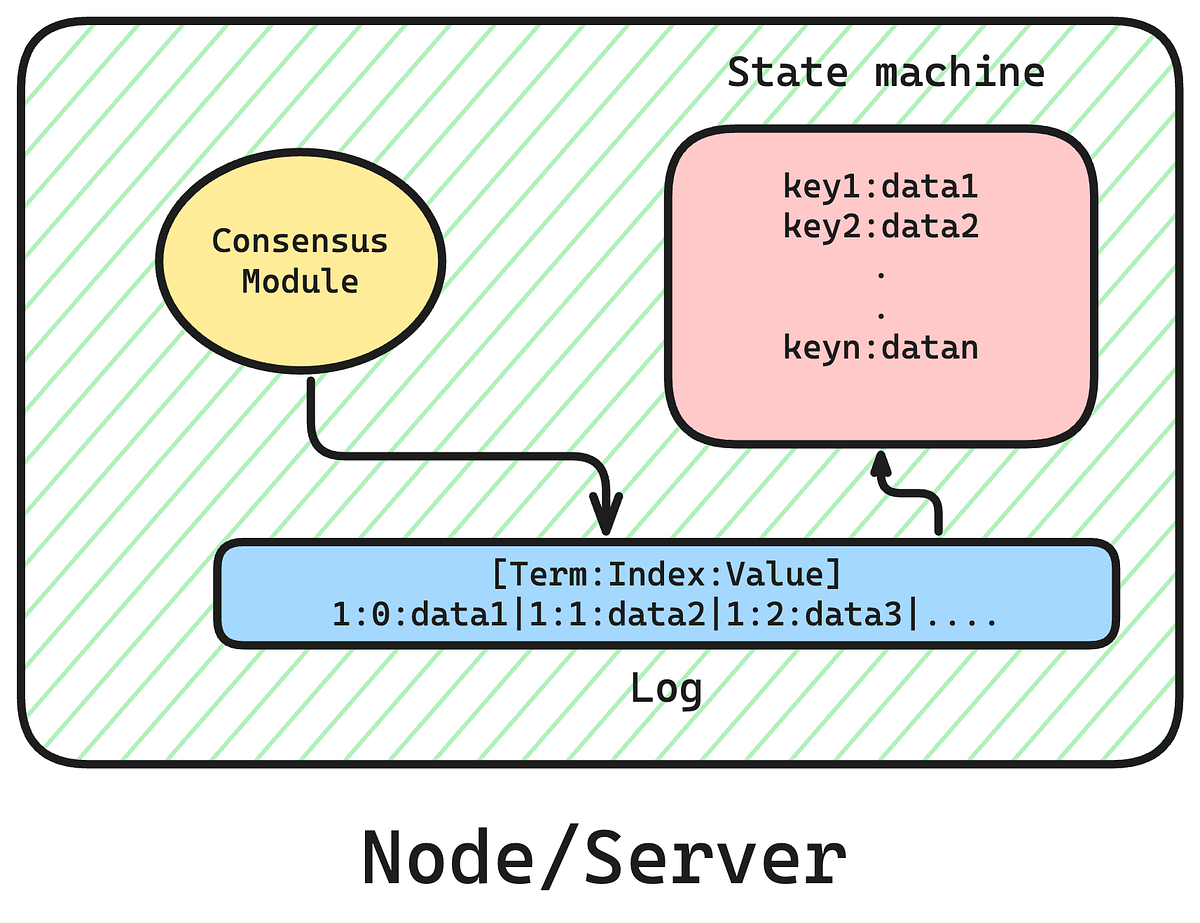
Консенсус Raft — як etcd залишається узгодженим
etcd використовує алгоритм консенсусу Raft для забезпечення узгодженості даних між вузлами кластера. Розглянемо, як це працює.
Ключові концепції Raft:
Чому непарна кількість вузлів?
etcd рекомендується розгортати у кластері з непарною кількістю вузлів (3, 5, 7). Розглянемо чому:
| Кількість вузлів | Кворум | Витримує відмов | Коментар |
|---|---|---|---|
| 1 | 1 | 0 | Немає відмовостійкості |
| 2 | 2 | 0 | Якщо один впаде — кворум втрачено |
| 3 | 2 | 1 | ✅ Оптимально для невеликих кластерів |
| 4 | 3 | 1 | Витримує стільки ж відмов, що й 3, але дорожче |
| 5 | 3 | 2 | ✅ Оптимально для production |
| 6 | 4 | 2 | Витримує стільки ж відмов, що й 5, але дорожче |
| 7 | 4 | 3 | ✅ Для критичних систем |
Висновок: Кластер з 4 вузлів витримує лише 1 відмову (так само, як 3 вузли), але споживає більше ресурсів. Тому завжди використовуйте непарну кількість.
Продуктивність та обмеження
etcd оптимізовано для узгодженості (consistency), а не для продуктивності. Типові характеристики:
- Пропускна здатність запису: ~10,000 записів/сек (залежить від розміру об'єктів)
- Латентність запису: 10-50 мс (залежить від мережі між вузлами)
- Розмір бази даних: рекомендовано до 8 ГБ (за замовчуванням ліміт — 2 ГБ)
- Кількість об'єктів: до ~100,000 Pod у кластері
Резервне копіювання etcd
Оскільки etcd — єдине джерело правди, регулярні резервні копії критично важливі:
# Створити snapshot etcd
ETCDCTL_API=3 etcdctl snapshot save /backup/etcd-snapshot.db \
--endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key
# Перевірити snapshot
ETCDCTL_API=3 etcdctl snapshot status /backup/etcd-snapshot.db
У production рекомендується автоматизувати резервне копіювання (наприклад, через CronJob у Kubernetes) та зберігати копії у віддаленому сховищі (S3, GCS).
kube-scheduler — планувальник розміщення
Коли у кластері зʼявляється новий Pod, якому ще не призначено вузол (статус Pending), завдання kube-scheduler — знайти для нього найбільш підходящий worker-вузол.
Scheduler не призначає вузол навмання. Він аналізує кожен доступний вузол і перевіряє цілий ряд умов через двофазний процес: фільтрація та оцінювання.
Процес планування: від Pending до Running
Фаза 1: Фільтрація (Predicate)
Scheduler перевіряє кожен вузол на відповідність обов'язковим вимогам. Якщо вузол не проходить хоча б одну перевірку — він виключається з розгляду.
requests Podʼу? Якщо Pod потребує 500m CPU, а на вузлі залишилось лише 200m — вузол відхиляється.- CPU вимірюється в мілікорах (m). 1000m дорівнює одному повному ядру процесора. Якщо Pod просить
500m, йому потрібно рівно половина потужності одного ядра. - Пам'ять вимірюється в байтах з префіксами. Найчастіше ви побачите Mi (Мебібайти, 1024 KB), на відміну від звичайних MB (1000 KB).
::
hostPort? Два Pod не можуть використовувати один і той самий hostPort на одному вузлі.nodeSelector? Наприклад, якщо Pod вимагає disktype=ssd, вузли без цієї мітки відхиляються. Це найпростіший спосіб сказати: "Хочу працювати тільки на вузлі з SSD".toleration для всіх taints вузла? Taint — це "табличка на дверях" вузла: "Тільки для GPU" або "Тут ремонт". Вузол відштовхує всі Pod, які не мають спеціальної перепустки (toleration).us-east-1a, вузли з інших зон відхиляються.::
Приклад фільтрації:
Кластер: 5 вузлів
Pod потребує: 2 CPU, 4 Gi RAM, мітка disktype=ssd
Вузол 1: 1 CPU доступно → ✗ Відхилено (PodFitsResources)
Вузол 2: 3 CPU, 8 Gi RAM → ✓ Пройшов
Вузол 3: 4 CPU, 6 Gi RAM, disktype=hdd → ✗ Відхилено (NodeSelector)
Вузол 4: 3 CPU, 8 Gi RAM, disktype=ssd → ✓ Пройшов
Вузол 5: 2 CPU, 4 Gi RAM, disktype=ssd → ✓ Пройшов
Результат фільтрації: [Вузол 2, Вузол 4, Вузол 5]
Фаза 2: Оцінювання (Scoring)
Серед вузлів, що пройшли фільтрацію, scheduler ранжує їх за балами (0-100). Вузол з найвищим балом обирається для розміщення Pod.
(capacity - requests) / capacity * 100. Мета — рівномірно розподілити навантаження.preferredDuringSchedulingIgnoredDuringExecution affinity правилам (м'які вимоги).Приклад оцінювання:
Вузли після фільтрації: [Вузол 2, Вузол 4, Вузол 5]
Вузол 2:
- LeastRequestedPriority: 60 балів (40% ресурсів зайнято)
- BalancedResourceAllocation: 80 балів (CPU 45%, RAM 40%)
- ImageLocalityPriority: 0 балів (образ не завантажено)
Загальний бал: (60 + 80 + 0) / 3 = 47 балів
Вузол 4:
- LeastRequestedPriority: 80 балів (20% ресурсів зайнято)
- BalancedResourceAllocation: 90 балів (CPU 22%, RAM 18%)
- ImageLocalityPriority: 100 балів (образ вже є)
Загальний бал: (80 + 90 + 100) / 3 = 90 балів ← Переможець
Вузол 5:
- LeastRequestedPriority: 50 балів (50% ресурсів зайнято)
- BalancedResourceAllocation: 70 балів (CPU 60%, RAM 40%)
- ImageLocalityPriority: 0 балів (образ не завантажено)
Загальний бал: (50 + 70 + 0) / 3 = 40 балів
Результат: Pod призначається Вузлу 4
Візуалізація процесу планування
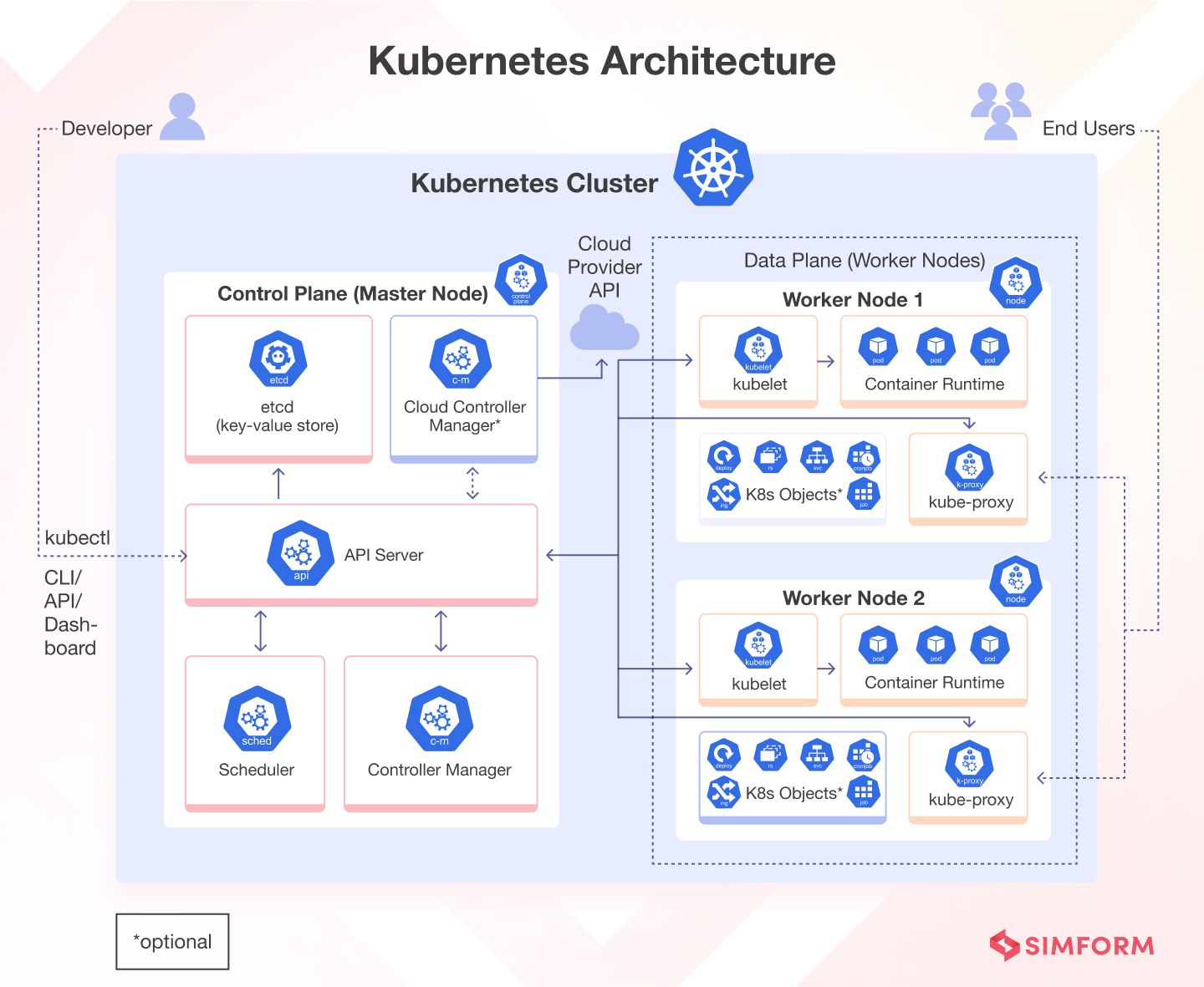
Що робити, якщо жоден вузол не підходить?
Якщо після фільтрації не залишилось жодного вузла — Pod залишається у стані Pending з причиною Unschedulable. Scheduler періодично повторює спробу планування (кожні кілька секунд).
Типові причини:
- Insufficient CPU/Memory: Немає вузлів з достатніми ресурсами
- No nodes available: Усі вузли мають taints, які Pod не толерує
- PersistentVolume not available: Немає доступних volumes у потрібній зоні
Переглянути причину:
kubectl describe pod <назва-podʼу>
У секції Events буде повідомлення на кшталт:
Warning FailedScheduling Pod cannot be scheduled: 0/3 nodes are available:
3 Insufficient cpu.
kube-controller-manager — двигун самовідновлення
Цей підхід має назву reconciliation loop (цикл узгодження) і є фундаментальним принципом Kubernetes. Уявіть це як круїз-контроль в автомобілі: ви виставляєте бажану швидкість (наприклад, 100 км/год), а система постійно перевіряє реальну швидкість і автоматично додає або скидає газ, щоб вона збігалася з вашим бажанням.
Reconciliation Loop — серце Kubernetes
Приклад: ReplicaSet Controller
Розглянемо, як ReplicaSet Controller підтримує задану кількість реплік:
Бажаний стан (Desired State):
ReplicaSet "nginx" має мати 3 репліки
Поточний стан (Current State):
Реально працює 2 Pod з міткою app=nginx
Розбіжність (Drift):
3 (бажано) - 2 (реально) = 1 (не вистачає)
Дія контролера (Reconciliation):
Створити 1 новий Pod через API-сервер
Новий стан:
3 репліки ✓ (стани збіглися)
Основні контролери у kube-controller-manager
У kube-controller-manager працює понад 20 контролерів. Розглянемо найважливіші:
NotReady. Якщо не відповідає 5 хвилин — евакуює Pod на інші вузли.backoffLimit).Приклад: Node Controller у дії
Розглянемо детально, як Node Controller реагує на недоступність вузла:
Таймлайн подій:
- 0 сек: Вузол 2 втрачає мережеве з'єднання
- 40 сек: Node Controller позначає вузол як
NotReady - 5 хв 10 сек: Node Controller видаляє Pod з недоступного вузла
- 5 хв 15 сек: Scheduler призначає нові Pod на здорові вузли
- 5 хв 30 сек: Kubelet на здорових вузлах запускає контейнери
kube-controller-manager:--node-monitor-period=5s— як часто перевіряти heartbeat--node-monitor-grace-period=40s— скільки чекати передNotReady--pod-eviction-timeout=5m— скільки чекати перед евакуацією Pod
Чому контролери працюють в одному процесі?
Усі контролери запускаються в одному процесі kube-controller-manager з кількох причин:
- Економія ресурсів: Спільне використання пам'яті та мережевих з'єднань до API-сервера
- Спрощення розгортання: Один бінарник замість десятків окремих процесів
- Узгоджена конфігурація: Всі контролери використовують одні й ті ж налаштування (kubeconfig, rate limits)
Але кожен контролер працює у власній goroutine (легковаговий потік у Go) і не блокує інші контролери.
Компоненти Worker Node
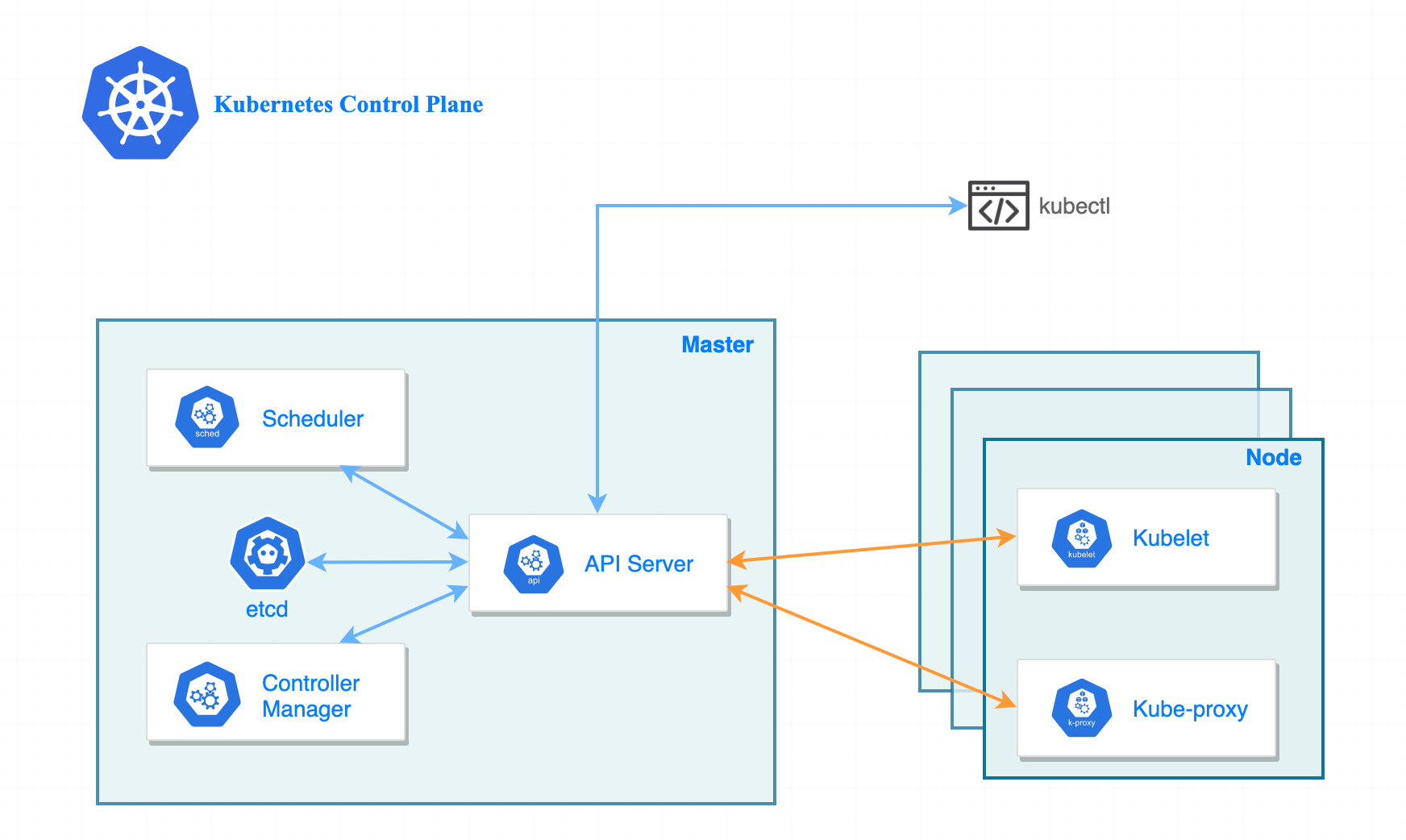
Якщо control plane — це мозок, що приймає рішення, то worker node — це тіло, що їх виконує. На кожному worker-вузлі запущені три компоненти Kubernetes.
kubelet — агент вузла
kubelet — це основний «агент» Kubernetes, який працює на кожному вузлі кластера. Його можна порівняти з виконробом (будівельним менеджером) на об'єкті: він отримує плани будівель (Pod Spec) від головного офісу (Control Plane) і стежить за тим, щоб робітники (Container Runtime) побудували все точно за схемою.
Він постійно спілкується з API-сервером: отримує список Podʼів, які мають виконуватись на його вузлі, і гарантує, що вони реально запущені та справні.
kubelet схожий на dockerd у тому сенсі, що саме він фізично запускає контейнери. Але замість того, щоб отримувати накази від вас напряму — він отримує їх від API-сервера у вигляді специфікацій Podʼів.Життєвий цикл Pod з точки зору kubelet
Основні обов'язки kubelet
restartPolicy.Взаємодія з Container Runtime через CRI
Kubelet не запускає контейнери напряму. Він використовує стандартний інтерфейс CRI (Container Runtime Interface) для взаємодії з container runtime (containerd, CRI-O).
Шари абстракції:
- Kubelet → отримує Pod Spec від API-сервера
- CRI (containerd) → перетворює Pod Spec у виклики container runtime
- OCI Runtime (runc) → створює Linux namespaces, cgroups та запускає процес
- Container Process → ваш застосунок працює в ізольованому середовищі
Статичні Pod (Static Pods)
Kubelet може запускати Pod не лише з API-сервера, а й з локальних файлів на вузлі. Це називається Static Pods.
# /etc/kubernetes/manifests/nginx.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-static
spec:
containers:
- name: nginx
image: nginx:1.25
Kubelet відстежує директорію /etc/kubernetes/manifests/ (налаштовується через --pod-manifest-path) та автоматично запускає Pod з файлів у цій директорії.
kubeadm. Файли kube-apiserver.yaml, etcd.yaml, kube-scheduler.yaml знаходяться у /etc/kubernetes/manifests/, і kubelet на control plane вузлі запускає їх як звичайні Pod.kube-proxy — мережевий проксі
kube-proxy відповідає за реалізацію мережевих правил на вузлі. Щоразу, коли у кластері створюється або видаляється Service (мережева абстракція для доступу до Pod), kube-proxy оновлює правила маршрутизації на своєму вузлі.
Як працює Service: від віртуальної IP до реальних Pod
Коли ви створюєте Service, Kubernetes призначає йому ClusterIP — віртуальну IP-адресу, яка не існує на жодному інтерфейсі. Завдання kube-proxy — перехопити трафік до цієї віртуальної IP та перенаправити його до реальних Pod.
Режими роботи kube-proxy
kube-proxy підтримує три режими реалізації мережевих правил:
Приклад iptables правил для Service:
# Service: nginx-service (ClusterIP: 10.96.0.10)
# Backends: 10.244.1.5:8080, 10.244.2.8:8080, 10.244.3.2:8080
# Правило 1: Перехопити трафік до ClusterIP
-A KUBE-SERVICES -d 10.96.0.10/32 -p tcp -m tcp --dport 80 -j KUBE-SVC-NGINX
# Правило 2: Балансування між Pod (33% ймовірність кожен)
-A KUBE-SVC-NGINX -m statistic --mode random --probability 0.33 -j KUBE-SEP-POD1
-A KUBE-SVC-NGINX -m statistic --mode random --probability 0.50 -j KUBE-SEP-POD2
-A KUBE-SVC-NGINX -j KUBE-SEP-POD3
# Правило 3: DNAT до реальних Pod
-A KUBE-SEP-POD1 -p tcp -m tcp -j DNAT --to-destination 10.244.1.5:8080
-A KUBE-SEP-POD2 -p tcp -m tcp -j DNAT --to-destination 10.244.2.8:8080
-A KUBE-SEP-POD3 -p tcp -m tcp -j DNAT --to-destination 10.244.3.2:8080
Container Runtime — виконавець контейнерів
Container Runtime — це програма, яка безпосередньо запускає контейнери. Kubernetes не запускає контейнери сам — він делегує цю роботу container runtime через стандартний інтерфейс CRI (Container Runtime Interface).
Еволюція: від Docker до containerd
Історично Kubernetes використовував Docker як container runtime. Але Docker — це повноцінна платформа з CLI, API, image registry тощо. Kubernetes потребував лише частину функціональності — запуск контейнерів.
Що змінилось у Kubernetes 1.24:
- ❌ Видалено
dockershim— проміжний шар між kubelet та Docker - ✅ Kubelet тепер спілкується з
containerdнапряму через CRI - ✅ Зменшено латентність запуску контейнерів (менше шарів абстракції)
- ✅ Спрощено архітектуру (менше компонентів)
docker build для створення образів. Образи, зібрані Docker, повністю сумісні з containerd, бо обидва дотримуються стандарту OCI (Open Container Initiative).CRI — Container Runtime Interface
CRI — це gRPC API, який визначає стандарт взаємодії. Уявіть це як стандартну розетку (USB). Kubernetes — це ноутбук, а Container Runtime (containerd, CRI-O) — це периферія. Завдяки CRI ви можете підключити будь-який сумісний runtime, не змінюючи код самого Kubernetes.
Основні операції CRI:
PullImage), видалення (RemoveImage), перегляд (ListImages).CreateContainer), запуск (StartContainer), зупинка (StopContainer), видалення (RemoveContainer).Приклад gRPC виклику через CRI:
// Kubelet → containerd
service RuntimeService {
rpc CreateContainer(CreateContainerRequest) returns (CreateContainerResponse);
rpc StartContainer(StartContainerRequest) returns (StartContainerResponse);
rpc StopContainer(StopContainerRequest) returns (StopContainerResponse);
rpc RemoveContainer(RemoveContainerRequest) returns (RemoveContainerResponse);
rpc ListContainers(ListContainersRequest) returns (ListContainersResponse);
rpc ContainerStatus(ContainerStatusRequest) returns (ContainerStatusResponse);
}
containerd — найпопулярніший CRI runtime
containerd — це високопродуктивний container runtime, який використовується у більшості Kubernetes-кластерів. Він є частиною CNCF (Cloud Native Computing Foundation) і підтримується спільнотою.
Архітектура containerd:
Роль кожного компонента:
- CRI Plugin: Реалізує CRI API для kubelet
- containerd Core: Управління життєвим циклом контейнерів, образами, snapshots
- containerd-shim: Проміжний процес між containerd та runc. Дозволяє containerd перезапускатись без впливу на контейнери
- runc: OCI-сумісний runtime, який створює Linux namespaces, cgroups та запускає процес
OCI — Open Container Initiative
OCI — це відкритий стандарт для контейнерів, який визначає:
- Image Spec: Формат образів контейнерів (layers, manifest, config)
- Runtime Spec: Як запускати контейнер (namespaces, cgroups, capabilities)
Завдяки OCI образи, зібрані Docker, працюють у containerd, CRI-O, Podman тощо. Всі вони дотримуються одного стандарту.
Приклад OCI Runtime Spec:
{
"ociVersion": "1.0.0",
"process": {
"terminal": false,
"user": { "uid": 0, "gid": 0 },
"args": ["nginx", "-g", "daemon off;"],
"env": ["PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"],
"cwd": "/"
},
"root": {
"path": "/var/lib/containerd/io.containerd.snapshotter.v1.overlayfs/snapshots/42/fs",
"readonly": false
},
"mounts": [
{ "destination": "/proc", "type": "proc", "source": "proc" },
{ "destination": "/dev", "type": "tmpfs", "source": "tmpfs" }
],
"linux": {
"namespaces": [
{ "type": "pid" },
{ "type": "network" },
{ "type": "ipc" },
{ "type": "uts" },
{ "type": "mount" }
],
"resources": {
"memory": { "limit": 268435456 },
"cpu": { "quota": 50000, "period": 100000 }
}
}
}
Цей JSON передається runc, який створює контейнер згідно зі специфікацією.
Альтернативи containerd
cri-dockerd — зовнішній адаптер CRI для Docker. Дозволяє продовжувати використовувати Docker як runtime.Повна картина: всі компоненти разом
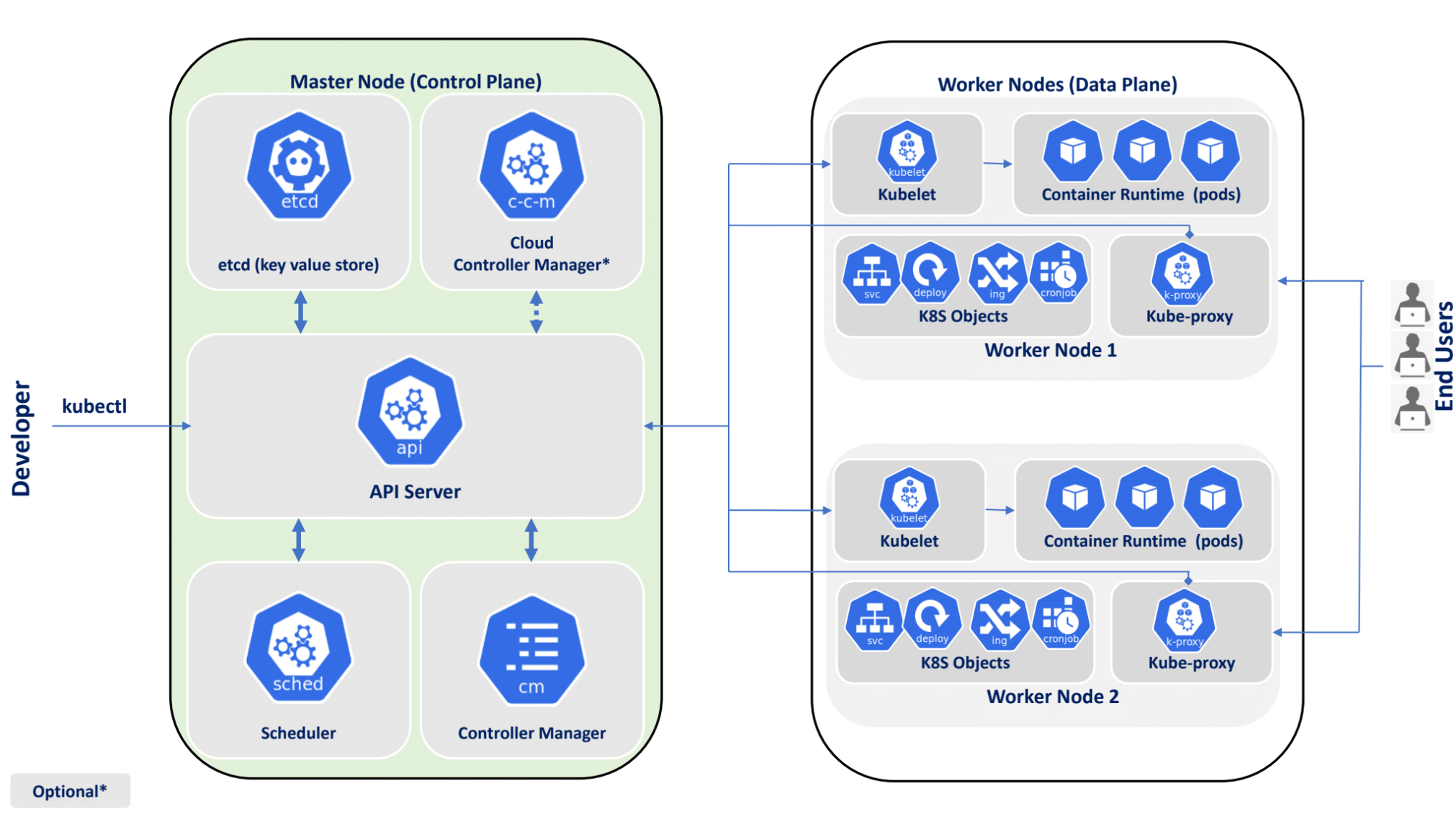
Тепер, коли кожен компонент детально розглянуто, подивимось на повну топологію кластера з усіма внутрішніми зв'язками:
Резюме
Kubernetes — це розподілена система з чіткою архітектурою. Кластер складається з двох типів вузлів:
- Control Plane:
kube-apiserver(єдина точка входу),etcd(сховище стану),kube-scheduler(планування Podʼів),kube-controller-manager(reconciliation loop) - Worker Nodes:
kubelet(агент вузла),kube-proxy(мережа),containerd(запуск контейнерів)
Pod — це найменша розгортана одиниця, обгортка над одним або кількома контейнерами.
Ключовий принцип — reconciliation loop: система безперервно порівнює бажаний стан з поточним і усуває розбіжності. Це основа self-healing.
У наступній статті ми переходимо від теорії до практики: встановимо локальний кластер за допомогою minikube та виконаємо перші команди kubectl.
Практичні завдання
Рівень 1 (Розуміння)
Завдання 1. Намалюйте (на папері або в будь-якому інструменті) схему Kubernetes-кластера з одним control plane вузлом і двома worker-вузлами. Позначте на кожному вузлі всі компоненти, що на ньому виконуються. Проведіть стрілки між компонентами, що взаємодіють між собою.
Завдання 2. Заповніть таблицю аналогій «Docker → Kubernetes»:
| Концепція Docker | Аналог у Kubernetes |
|---|---|
dockerd | ? |
docker CLI | ? |
| Контейнер | ? |
docker run | ? |
docker ps | ? |
Рівень 2 (Аналіз)
Завдання 3. Ваш кластер має один control plane вузол і три worker-вузли. Worker Node 2 раптово стає недоступним. Опишіть покроково: який компонент першим виявляє проблему, яким чином, що відбувається з Podʼами, що виконувались на цьому вузлі, і скільки орієнтовно часу займе відновлення.
Завдання 4. Чому etcd рекомендується розгортати у кластері з непарною кількістю вузлів (3, 5, 7)? Знайдіть відповідь у концепції «кворум» (quorum) у розподілених системах та поясніть своїми словами: що відбудеться з кластером з 4 вузлями etcd, якщо одночасно впадуть 2?
Рівень 3 (Архітектурне мислення)
Завдання 5. Ви проектуєте production-кластер для критичного застосунку з вимогою 99.99% uptime. Визначте мінімальну топологію: скільки вузлів control plane та скільки worker-вузлів потрібно, щоб витримати одночасний вихід з ладу одного control plane вузла і одного worker-вузла без деградації сервісу? Поясніть логіку свого рішення.
Kubernetes — коли Docker Compose більше не вистачає
Від одного сервера до кластера — чому виникає потреба в оркестрації, що таке Kubernetes і яке місце він займає у сучасній інфраструктурі
Локальне середовище — minikube, kind та k3s
Встановлення та налаштування локального Kubernetes-кластера для розробки та навчання