Проблеми Спільного Стану — Race Condition та Data Race
Проблеми Спільного Стану
Вступ: Чому Багатопоточність Небезпечна
Ви вже знаєте, як створювати потоки, запускати їх та дочекатися завершення. Здається — нічого складного: розбили задачу на частини, запустили паралельно, зібрали результати. Але є одна категорія помилок, що робить багатопоточне програмування по-справжньому складним. Ця категорія — проблеми спільного стану.
Уявіть собі таку ситуацію з реального життя. Два касири в банку працюють одночасно. Клієнт А приходить до першого касира і просить зняти 1000 грн. Клієнт Б — до другого касира і також просить зняти 1000 грн. На рахунку спочатку є рівно 2000 грн. Кожен касир перевіряє залишок, бачить 2000 грн, виконує операцію і видає гроші. Разом вони видали 2000 грн. Але якщо обидва касири перевірили рахунок одночасно, ще до того як хтось встиг записати зміну — вони обидва побачать 2000, обидва вирішать "залишку достатньо" і видадуть гроші. Після двох операцій на рахунку залишиться 1000 грн замість правильного нуля, або ж рахунок піде в мінус. Гроші з'явились нізвідки.
Саме цей сценарій відбувається у програмному коді, коли кілька потоків неузгоджено звертаються до спільних даних. І найжахливіше — ця помилка може не проявлятися роками, а потім раптово виникнути у production у найнесподіваніший момент.
Ця тема — детальний розбір того, які саме речі можуть піти не так, коли потоки ділять дані між собою. Розуміння проблем є обов'язковою передумовою перед вивченням синхронізації у наступній темі. Не можна правильно застосовувати ліки, не розуміючи хвороби.
Race Condition: Результат Залежить від Гонки
Що Таке Race Condition
Race Condition (стан гонки) — це дефект програми, при якому коректність результату залежить від відносного порядку або часу виконання операцій двома або більше потоками. Іншими словами, програма дає правильний результат лише "пощастило" з порядком виконання, але в іншому розкладі — результат хибний.
Термін "Race" (гонка) дуже влучний: уявіть, що два потоки буквально "змагаються" за право першого виконати операцію. Переможець-потік впливає на те, яким буде кінцевий стан. Якщо "правильний" потік перемога — програма працює. Якщо "неправильний" — виникає баг.
Банківський Рахунок: Класичний Приклад
Розберемо найпопулярніший приклад — одночасне списання коштів з банківського рахунку:
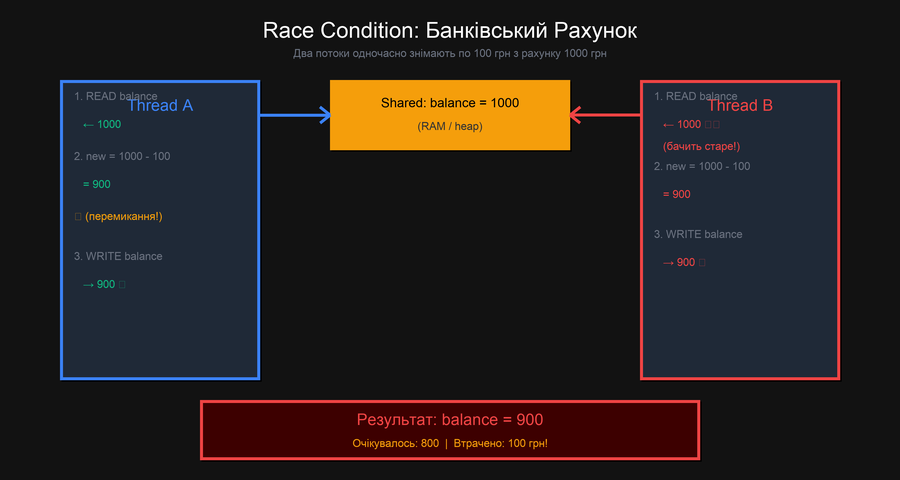
На схемі чітко видно проблему: обидва потоки читають баланс до того як будь-який з них встигає записати зміну. У результаті обидва "думають", що виконали коректну операцію, але разом "загубили" 100 грн.
public class BankAccount
{
// ❌ НЕБЕЗПЕЧНО: не захищений спільний стан
private decimal _balance;
public BankAccount(decimal initialBalance)
{
_balance = initialBalance;
}
public bool TryWithdraw(decimal amount)
{
// Крок 1: CHECK — перевірка умови (READ)
if (_balance < amount)
return false;
// ⚡ ЯКЩО ТУТ ВІДБУДЕТЬСЯ ПЕРЕМИКАННЯ КОНТЕКСТУ — виникне Race Condition!
// Між перевіркою і зміною потік може бути витісненим планувальником.
// Другий потік пройде перевірку з тим самим балансом.
// Крок 2: ACT — виконання дії (WRITE)
_balance -= amount;
return true;
}
public decimal Balance => _balance;
}
// Демонстрація проблеми:
var account = new BankAccount(1000);
int successCount = 0;
var tasks = Enumerable.Range(0, 10).Select(_ => Task.Run(() =>
{
for (int i = 0; i < 100; i++)
{
// 10 потоків * 100 разів намагаються зняти по 1 грн
if (account.TryWithdraw(1))
Interlocked.Increment(ref successCount);
}
}));
await Task.WhenAll(tasks);
Console.WriteLine($"Баланс: {account.Balance}"); // може бути від'ємним!
Console.WriteLine($"Знято: {successCount} разів"); // може бути більше 1000
// Очікувалось: Balance = 0, successCount = 1000
// Отримаємо: Balance < 0 або successCount > 1000 (Race Condition!)
Патерн Check-then-Act: Де Ховається Пастка
Race Condition у прикладі вище — це конкретний підвид відомого антипатерну check-then-act (перевір-потім-виконай). Цей патерн виглядає природно і здавалося б безпечно, але є фундаментально небезпечним у багатопоточному контексті:
// Загальна форма check-then-act:
// if (condition_is_true) // ← READ (перевірка)
// perform_action(); // ← WRITE (дія)
// Між READ і WRITE — "вікно вразливості" (window of vulnerability)
// Будь-який інший потік може змінити стан у цьому вікні
// Приклад 1: Singleton (небезпечний)
private static MyService? _instance;
public static MyService GetInstance()
{
if (_instance is null) // READ: перевірка
{ // ← вікно вразливості!
_instance = new MyService(); // WRITE: ініціалізація
}
return _instance;
}
// Якщо два потоки одночасно пройдуть перевірку:
// → два об'єкти будуть створені
// → один буде одразу замінений → ресурс витрачений даремно
// → або, якщо MyService тримає зовнішні ресурси, → resource leak
// Приклад 2: Перевірка файлу перед відкриттям (TOCTOU — Time of Check / Time of Use)
if (File.Exists("config.json")) // CHECK
{
var content = File.ReadAllText("config.json"); // USE
// ← Між CHECK і USE: файл може бути видалений іншим процесом!
// → FileNotFoundException у "перевіреному" коді
}
// Безпечний підхід: спробувати виконати дію напряму і обробити виключення
try
{
var content = File.ReadAllText("config.json"); // Одна атомарна операція
// ...
}
catch (FileNotFoundException)
{
// Обробляємо відсутність файлу
}
Check-then-Act у Реальних Системах: TOCTOU
Окремий клас check-then-act помилок настільки поширений, що отримав власну назву: TOCTOU (Time of Check / Time of Use — Час Перевірки / Час Використання). Класичний приклад — безпековий баг:
1. Програма перевіряє: чи має користувач права на файл? ← Check
2. Між перевіркою і дією зловмисник підмінює файл! ← Window
3. Програма читає файл, думаючи що він "перевірений" ← Use
У C#-коді TOCTOU виникає при роботі з файлами, портами, мережевими з'єднаннями — скрізь де стан зовнішнього ресурсу може змінитись між перевіркою і використанням.
Data Race: Одночасний Доступ до Пам'яті
Відмінність від Race Condition
Data Race і Race Condition — пов'язані, але різні поняття. Плутанина між ними дуже поширена, тому важливо чітко розмежувати:
- Data Race — технічний стан: два або більше потоки звертаються до однієї ділянки пам'яті одночасно, і хоча б один доступ — це запис, і між ними немає синхронізації. Це визначення на рівні залізного стандарту пам'яті (C++ memory model, Java memory model, .NET memory model).
- Race Condition — логічний дефект: результат програми залежить від недетермінованого порядку операцій. Може існувати без Data Race (наприклад, через check-then-act з атомарними операціями, що дають неправильний порядок). Може існувати разом з Data Race.
Щоб не плутатись, скористаємось аналогією. Data Race — це як якщо двоє людей одночасно намагаються дописати в один щоденник (фізичний конфлікт запису). Race Condition — це як якщо двоє людей читають та виконують дії на підставі розкладу поїздів, що міг змінитись між читанням і поїздкою (логічний конфлікт стану).
i++ — Не Атомарна Операція
Найвідоміший і найбільш недооцінений приклад Data Race — звичайний інкремент i++. Він виглядає як одна операція, але на рівні процесора — це три окремі кроки:
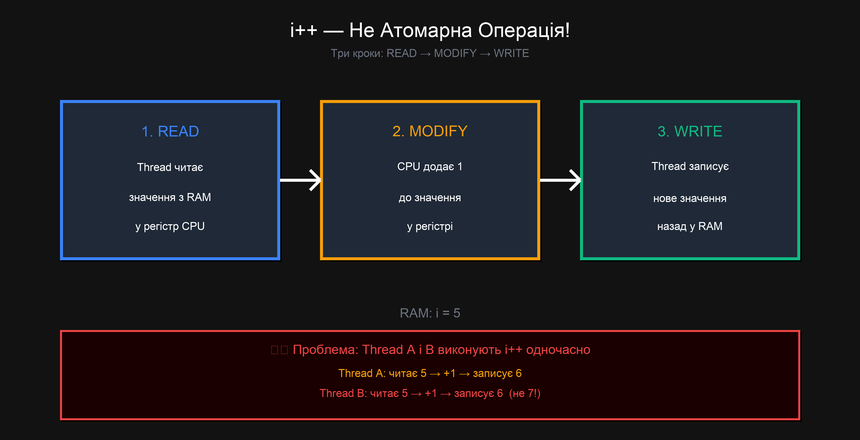
// Дивимось що насправді робить i++:
// На рівні CIL (Common Intermediate Language):
// ldloc.0 ← завантажити 'i' зі стекy/пам'яті у стек СLR
// ldc.i4.1 ← завантажити константу 1
// add ← додати
// stloc.0 ← зберегти результат назад у пам'ять
// На рівні x64 машинного коду:
// MOV eax, [rbp-4] ; READ: скопіювати 'i' у регістр
// ADD eax, 1 ; MODIFY: додати 1 до регістра
// MOV [rbp-4], eax ; WRITE: записати результат назад у пам'ять
Між будь-якими двома з цих трьох кроків планувальник ОС може переключити контекст і запустити інший потік. Якщо другий потік виконає всі три кроки, поки перший "застряг" між READ та WRITE — обидва запишуть "старе + 1", а не "старе + 2":
int counter = 0;
// Запускаємо 10 потоків, кожен робить 100_000 інкрементів
// Очікуємо: 10 * 100_000 = 1_000_000
var threads = Enumerable.Range(0, 10).Select(_ =>
new Thread(() =>
{
for (int i = 0; i < 100_000; i++)
counter++; // ← DATA RACE тут!
})
).ToList();
threads.ForEach(t => t.Start());
threads.ForEach(t => t.Join());
Console.WriteLine($"Очікувалось: 1,000,000");
Console.WriteLine($"Отримали: {counter:N0}");
// Типовий результат: 312,847 або 578,442 — менше 1_000_000!
// Результат різний при кожному запуску.
Чому Результат МЕНШЕ Очікуваного
Важливо зрозуміти не просто "так трапляється", а чому логіка дає саме такий результат. Кожен "загублений" інкремент — це ситуація де два потоки прочитали одне й те саме значення і обидва записали "значення + 1". Тобто два інкременти дали результат лише одного. Кількість "загублених" інкрементів залежить від кількості таких конфліктів, що, в свою чергу, залежить від кількості ядер, розкладу планувальника і навіть від тривалості виконання — тому і результат кожен раз різний.
На машині з одним ядром Race Condition все одно можлива — переключення контексту може відбутись між MOV eax та ADD eax. На багатоядерній машині ситуація гірша: два потоки можуть буквально одночасно виконувати різні фази READ-MODIFY-WRITE на різних ядрах.
Undefined Behavior у .NET Memory Model
На відміну від C/C++, де Data Race є Undefined Behavior (буквально: поведінка невизначена стандартом, компілятор може робити що завгодно), у .NET Data Race не є UB у тому самому сенсі. CLR гарантує певний мінімальний рівень безпеки:
- Поля посилальних типів (reference type fields) завжди або видимі коректно, або повністю невидимі — ніколи "наполовину"
- Типи розміром ≤ розміру native pointer (int, IntPtr, тощо на відповідній платформі) є атомарними щодо читання/запису самого значення
Але жодних гарантій порядку і жодних гарантій видимості між потоками без явної синхронізації. На практиці це означає: код може давати неправильні результати, але не буде "вибухати" у сенсі запису по чужих адресах.
Visibility Problem: Коли Один Потік не Бачить Зміни Іншого
Ієрархія Кешу CPU та її Вплив
Щоб зрозуміти Visibility Problem, потрібно знати як влаштована пам'ять сучасного процесора. Доступ до RAM займає сотні наносекунд — це "вічність" для CPU, що виконує мільярди операцій за секунду. Тому процесори мають багаторівневий кеш:
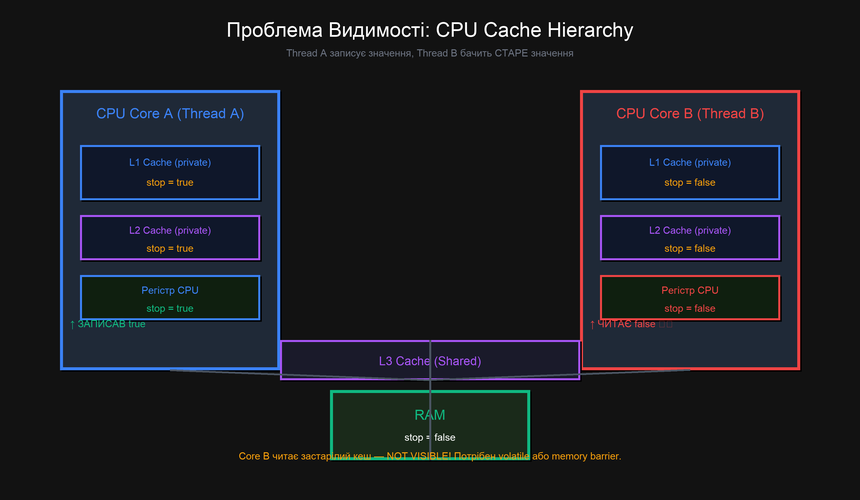
- L1 Cache (~32-64 KB): є у кожного ядра окремо, доступ ~4-5 тактів (~1-2 нс)
- L2 Cache (~256 KB – 1 MB): є у кожного ядра окремо, доступ ~12 тактів (~4 нс)
- L3 Cache (~8-32 MB): спільний для всіх ядер, доступ ~40 тактів (~13 нс)
- RAM: спільна, доступ ~200 тактів (~65 нс)
Ключовий момент: L1 і L2 — приватні для кожного ядра. Якщо Thread A (на Core 0) записав значення у свій L1 кеш, воно не одразу стає видимим у L1 кеші Core 1, де виконується Thread B. Протокол когерентності кешу (MESI) зрештою синхронізує їх — але не гарантовано, що це станеться до наступного читання Thread B.
Демонстрація: boolean Flag
Класична демонстрація Visibility Problem — прапорець зупинки між потоками:
using System.Threading;
// ❌ НЕБЕЗПЕЧНО: звичайне поле, без гарантій видимості
bool _stop = false;
var worker = new Thread(() =>
{
long iterations = 0;
while (!_stop) // Worker читає _stop зі СВОГО КЕШУ (або регістра)
{
iterations++;
// Без синхронізації: JIT може кешувати _stop у регістрі
// і ніколи не перечитувати його з RAM!
}
Console.WriteLine($"Worker зупинився після {iterations} ітерацій");
});
worker.Start();
Thread.Sleep(1000);
_stop = true; // Main thread записує _stop у СВІЙ КЕШ
Console.WriteLine("Main: записали _stop = true");
worker.Join(2000);
if (worker.IsAlive)
{
Console.WriteLine("Worker досі виконується! Visibility Problem!");
// У деяких конфігураціях (особливо Release build на multi-core)
// Worker НІКОЛИ не побачить _stop = true!
}
Роль JIT та Оптимізацій
Проблема видимості виникає не лише через апаратний кеш, але і через оптимізації компілятора (JIT):
bool _ready = false;
// Що JIT бачить:
void WorkerBody()
{
while (!_ready) { } // простий цикл очікування
DoWork();
}
// Що JIT може згенерувати (оптимізована версія):
void WorkerBodyOptimized()
{
if (!_ready) while (true) { } // ← читання _ready ОДИН РАЗ,
DoWork(); // потім нескінченний цикл якщо false!
}
// JIT бачить: "в цьому методі ніхто не пише в _ready → значення не змінюється
// → безпечно кешувати в регістрі і не перечитувати"
// З точки зору однопоточної семантики — це КОРЕКТНА оптимізація!
Саме тому volatile ключове слово існує: воно забороняє JIT кешувати значення у регістрі і гарантує читання напряму з пам'яті при кожному зверненні. Детально — нижче.
Happens-Before: Формальна Модель
Для розуміння гарантій видимості у .NET існує формальна концепція happens-before (відбувається-до):
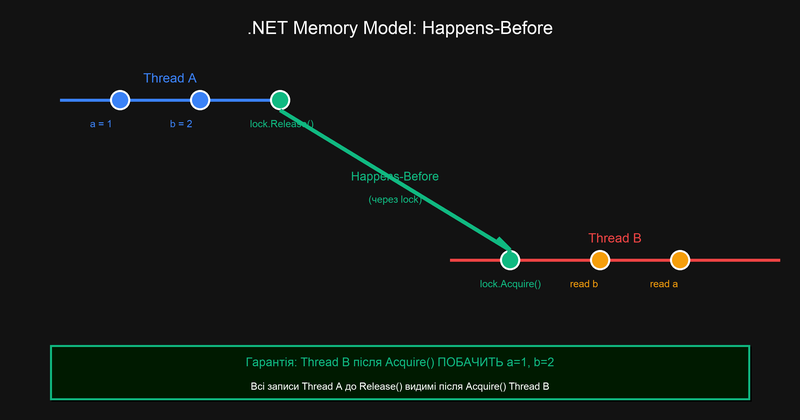
Якщо операція A happens-before операція B, це гарантує:
- A виконається до B у часі (з точки зору системи)
- Всі записи у пам'ять, зроблені A або будь-якою операцією до A, будуть видимі операції B
У .NET happens-before встановлюється кількома механізмами:
Thread.Start()happens-before перша операція нового потокуThread.Join()— всі операції завершеного потоку happens-before повернення з Joinlockrelease happens-before наступнийlockacquire того ж об'єктаvolatilewrite happens-before наступнийvolatileread того ж поляInterlockedоперації мають sequential consistency
Без будь-якого з цих механізмів — жодних гарантій видимості між потоками. Саме це означає "без синхронізації".
Torn Read: Часткове Зчитування
Атомарність Запису у Пам'ять
Torn Read (розірване читання) — ситуація, коли одне логічне значення записується у пам'ять кількома окремими операціями запису, і читач може прочитати "половину" нового і "половину" старого значення — значення, що ніколи насправді не існувало.
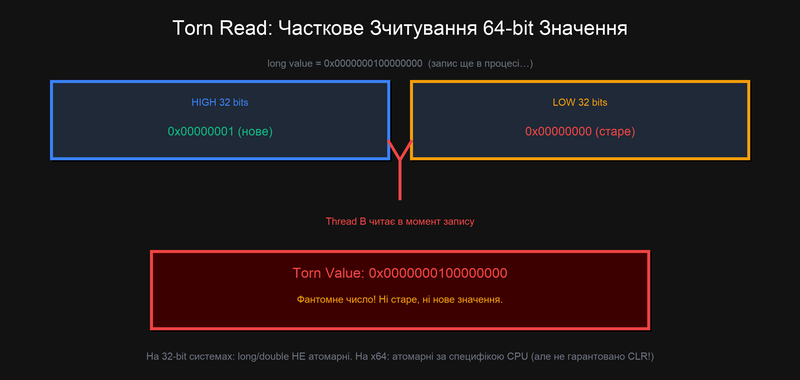
Це звучить фантастично, але є реальною проблемою на певних архітектурах:
// На 32-bit системі або з x86 CIL, запис long може бути не атомарним!
// CLR НЕ гарантує атомарність long і double на всіх платформах.
long _sharedLong = 0;
// Thread A: записує нове значення
// На 32-bit: цей запис = дві 32-bit операції:
// [HIGH 32 bits] ← 0x00000001
// [LOW 32 bits] ← 0x00000000
// Між цими двома записами — вікно вразливості!
_sharedLong = 0x0000000100000000L;
// Thread B: читає у той момент коли Thread A записав тільки HIGH half:
long value = _sharedLong;
// value може бути = 0x0000000100000000 (нове, правильне)
// або 0x0000000000000000 (старе, правильне)
// або 0x0000000100000000 (torn! HIGH від нового, LOW від старого)
// Torn значення ніколи не існувало! Це фантомне число.
Де Torn Reads Можуть Виникнути
| Тип | x64 .NET | x86 .NET | Пояснення |
|---|---|---|---|
int, uint | ✅ Atomic | ✅ Atomic | 32-bit, вирівняне |
long, ulong | ✅ Atomic* | ❌ Non-atomic | 64-bit на 32-bit ALU |
double | ✅ Atomic* | ❌ Non-atomic | Аналогічно |
float | ✅ Atomic | ✅ Atomic | 32-bit |
decimal | ❌ Non-atomic | ❌ Non-atomic | 128-bit (3 окремих поля) |
struct | ❌ Non-atomic | ❌ Non-atomic | Завжди кілька полів |
bool, byte, sbyte | ✅ Atomic | ✅ Atomic | ≤ 32-bit |
* Атомарно при правильному вирівнюванні (aligned). CLR гарантує вирівнювання для полів, але не для всіх комбінацій.
long і double в більшості випадків є атомарними на рівні залізниці, CLR не гарантує цього в специфікації. Специфікація гарантує атомарність лише для типів розміром ≤ IntPtr.Size. Для portable коду — використовуйте Interlocked або volatile для будь-яких спільних полів.Приклад: Torn Double
// Структура з двома полями — ЗАВЖДИ torn (не атомарна)
public struct ComplexNumber
{
public double Real;
public double Imaginary;
// 16 байт разом — жодна платформа не записує це атомарно!
}
ComplexNumber _shared = new(0, 0);
// Thread A: записує нове значення
void WriterThread()
{
while (true)
_shared = new ComplexNumber(1.0, 2.0); // Записує Real, потім Imaginary
}
// Thread B: читає значення
void ReaderThread()
{
while (true)
{
double r = _shared.Real;
double i = _shared.Imaginary;
// Можливі "рівні":
// (0, 0) — старе ✓
// (1, 2) — нове ✓
// (1, 0) — torn! Real від нового, Imaginary від старого ✗
// (0, 2) — torn! Real від старого, Imaginary від нового ✗
if (!((r == 0 && i == 0) || (r == 1.0 && i == 2.0)))
Console.WriteLine($"Torn read виявлено! {r}, {i}");
}
}
Memory Reordering: Коли CPU "Перегортає" Інструкції
Out-of-Order Execution
Сучасні процесори (Intel, AMD, ARM) не виконують інструкції строго в тому порядку, в якому їх записав програміст. Для максимальної продуктивності CPU виконує Out-of-Order Execution — самостійно переставляє інструкції, що не залежать одна від одної, щоб краще завантажити виконавчі блоки (ALU, FPU, Load/Store unit).
З точки зору одного потоку це абсолютно безпечно: CPU гарантує, що кінцевий результат буде таким самим, як якщо б інструкції виконувались у оригінальному порядку. Але з точки зору іншого потоку на іншому ядрі — він може бачити ефекти операцій у переставленому порядку.
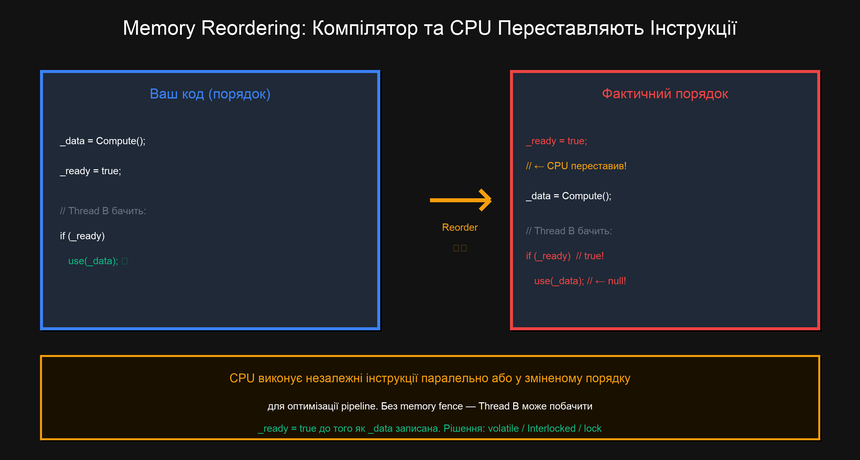
Класичний Приклад: Double-Checked Locking Bug
Найвідоміший прояв Memory Reordering — "зламаний Double-Checked Locking" у .NET Framework до 2.0:
// ❌ ЗЛАМАНО в .NET 1.x (без volatile):
public class Singleton
{
private static Singleton? _instance;
private static readonly object _lock = new object();
public static Singleton GetInstance()
{
if (_instance is null) // перша перевірка (без lock)
{
lock (_lock)
{
if (_instance is null) // друга перевірка (з lock)
{
_instance = new Singleton();
// new Singleton() = три кроки:
// 1. Виділити пам'ять
// 2. Ініціалізувати поля (викликати конструктор)
// 3. Записати адресу у _instance
// CPU/JIT можуть виконати кроки 1, 3, 2 (переставити 2 і 3!)
}
}
}
return _instance; // ← може повернути не повністю ініціалізований об'єкт!
}
}
Якщо CPU виконає кроки у порядку 1→3→2 (адреса записана ДО ініціалізації полів), то інший потік побачить _instance != null (пройде першу перевірку) але отримає об'єкт з не-ініціалізованими полями. Це Torn Read + Memory Reordering разом.
// ✅ ПРАВИЛЬНО: volatile забороняє reordering навколо присвоєння
public class SingletonCorrect
{
private static volatile SingletonCorrect? _instance;
private static readonly object _lock = new object();
public static SingletonCorrect GetInstance()
{
if (_instance is null)
{
lock (_lock)
{
if (_instance is null)
_instance = new SingletonCorrect(); // volatile запобігає reorder
}
}
return _instance;
}
}
// ✅ АБО: Lazy<T> — найчистіший підхід
public class SingletonLazy
{
private static readonly Lazy<SingletonLazy> _lazy =
new(() => new SingletonLazy(), LazyThreadSafetyMode.ExecutionAndPublication);
public static SingletonLazy Instance => _lazy.Value;
}
Store Buffer та Store-Load Reordering
На процесорах Intel x86/x64 найчастіший вид reordering — Store-Load: CPU може виконати Load (читання) до попереднього Store (запису) якщо вони стосуються різних адрес:
// Код Thread A: // Код Thread B:
x = 1; y = 1;
r1 = y; r2 = x;
// Без memory barrier: r1==0 і r2==0 одночасно — теоретично можливо!
// (обидва потоки прочитали "старе" значення до того як запис став видимим)
Це здається неможливим, але Intel Software Developer Manual явно допускає такий сценарій через Store Buffer — буфер між ядром і кешем, куди записи йдуть спочатку і звідки їх не завжди одразу бачать інші ядра.
Lost Update: Загублене Оновлення
Lost Update — це конкретний наслідок Data Race при патерні Read-Modify-Write без синхронізації. Технічно він вже підпадає під Race Condition і Data Race, але виділяється окремо через практичну важливість:
// Сценарій: два потоки читають рахунок і нараховують бонуси
int _loyaltyPoints = 0;
// Thread A: "нарахувати 50 балів"
int current_a = _loyaltyPoints; // READ: 0
int new_a = current_a + 50; // MODIFY: 0 + 50 = 50
// ← Thread B виконується тут! Читає 0, нараховує 30, записує 30
_loyaltyPoints = new_a; // WRITE: 50 (перезаписує результат Thread B!)
// Thread B: "нарахувати 30 балів"
int current_b = _loyaltyPoints; // READ: 0 (ще до запису Thread A)
int new_b = current_b + 30; // MODIFY: 0 + 30 = 30
_loyaltyPoints = new_b; // WRITE: 30
// Очікуваний результат: 80 (50 + 30)
// Фактичний результат: або 30, або 50 — оновлення одного потоку ЗАГУБЛЕНО!
Lost Update відрізняється від простого i++ тим, що між READ і WRITE може бути значна бізнес-логіка. Це може не виглядати як простий "інкремент" і тому важче помітити.
Підсумок: Таксономія Проблем

Зведемо всі проблеми у систему:
Race Condition
lock, атомарні операції Interlocked, рефакторинг без check-then-act.Data Race
i++ без синхронізації — завжди Data Race.
Рішення: lock, Interlocked, volatile (для простого read/write).Visibility Problem
volatile, Interlocked, lock.Memory Reordering
volatile, Thread.MemoryBarrier(), lock.Torn Read
long/double на 32-bit системах; будь-який struct.
Рішення: Interlocked, lock, volatile (для примітивів).Lost Update
Interlocked.Increment vs counter++ — різниця у результаті.
Рішення: Interlocked.Add/CompareExchange, lock.Практичні Завдання
Рівень 1: Відтворення Race Condition
Реалізуйте програму з BankAccount (метод TryWithdraw) і запустіть 20 потоків, що одночасно намагаються знімати кошти. Виведіть початковий баланс, кількість неправильних зняттів та кінцевий баланс. Переконайтеся що баланс стає від'ємним або successCount перевищує ліміт.
Рівень 2: Вимір Втрат від Data Race
Напишіть тест CounterBenchmark:
- Запустіть 8 потоків, кожен інкрементує спільний
int counter1_000_000 разів (без синхронізації) - Порахуйте скільки "загублено" інкрементів
- Виміряйте час виконання
- Повторіть з
Interlocked.Increment— порахуйте overhead синхронізації
Рівень 3: Виявлення Visibility Problem
Відтворіть Visibility Problem:
- Запустіть потік з
while (!_stop)і лічильником ітерацій - Через 1 секунду присвойте
_stop = true - Зробіть
thread.Join(3000)— перевірте чи він зупинився - Спробуйте різні варіанти: Debug vs Release build, з
volatileі без - Задокументуйте різницю в поведінці
Потоки — Lifecycle, Пріоритети та Безпечне Завершення
ThreadState і повний lifecycle потоку, система пріоритетів та Priority Inversion, чому Thread.Abort небезпечний і як правильно зупиняти потоки через CancellationToken. Наскрізний приклад — паралельний прайм-сканер з graceful shutdown.
Проблеми Спільного Стану — Memory Model та volatile
.NET Memory Model у деталях — acquire/release семантика, volatile та її обмеження, Interlocked як перший крок до безпечного коду, Thread.MemoryBarrier і наскрізний приклад Producer-Consumer без синхронізаційних примітивів.