Алгоритми сортування та аналіз складності
Навіщо вчити сортування?
Сортування — одна з найбільш фундаментальних і досліджуваних задач в інформатиці. Не тому що воно рідко зустрічається в реальному житті (навпаки — воно всюди: ранжування у пошуку, стрічки соціальних мереж, ціни в інтернет-магазині), а тому що пошук ефективного способу впорядкувати дані навчив людство думати про складність алгоритмів.
Кожен алгоритм сортування — це маленький філософський трактат: «Яку ціну ми платимо за порядок?» Різні алгоритми відповідають на це питання по-різному. Один витрачає менше порівнянь, інший — менше переміщень, третій краще працює на майже-відсортованих даних. Щоб порівнювати algorithms чесно, нам потрібна єдина мова вимірювання — і ця мова називається Big O.
Big O нотація: мова складності
Проблема вимірювання
Як виміряти швидкість алгоритму? Перше, що спадає на думку — засікти час виконання на комп'ютері. Але це поганий підхід: час залежить від процесора, оперативної пам'яті, поточного навантаження системи, компілятора, оптимізацій. Один і той самий алгоритм на старому ноутбуці займе 5 секунд, на сервері — 0.1 секунди. Як же порівнювати?
Відповідь: вимірювати не час, а кількість операцій — і залежність цієї кількості від розміру вхідних даних.
Big O нотація (нотація «О велике») — математична мова для опису цієї залежності. Вона показує, як зростає час (або пам'ять) алгоритму при збільшенні розміру вхідних даних n — у найгіршому випадку.
n. 100n і n — обидва O(n), бо при пересуванні від тис. до млн. елементів і той, і інший збільшаться у 1000 разів.Основні класи складності
Розглянемо основні класи Big O від найшвидшого до найповільнішого:
O(1) — Константна складність. Кількість операцій не залежить від розміру вхідних даних. Незалежно від того, скільки елементів у масиві — дія завжди займає однаковий час.
int firstElement = arr[0]; // Завжди одна операція
O(log n) — Логарифмічна складність. З кожною операцією задача вдвічі зменшується. Бінарний пошук у відсортованому масиві: шукаємо серед 1 000 000 елементів — потрібно не більше 20 порівнянь (бо 2²⁰ ≈ 1 000 000).
O(n) — Лінійна складність. Кількість операцій прямо пропорційна розміру вхідних даних. Пошук у невідсортованому масиві: в найгіршому випадку потрібно перевірити кожен елемент.
for (int i = 0; i < n; i++) { /* одна операція */ } // O(n)
O(n log n) — Лінійно-логарифмічна складність. «Золотий стандарт» порівняльного сортування. Швидке сортування та сортування злиттям. Значно ефективніший за O(n²) на великих даних.
O(n²) — Квадратична складність. Два вкладені цикли на одних і тих самих даних. Прийнятна на малих масивах (до кількох тисяч елементів), але катастрофічна на великих: мільйон елементів → 10¹² операцій.
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++) { /* одна операція */ } // O(n²)
Наочне порівняння: що відбувається при n = 1 000 000?
| Big O | Кількість операцій | Час (≈1 млрд ops/сек) |
|---|---|---|
| O(1) | 1 | миттєво |
| O(log n) | ≈ 20 | миттєво |
| O(n) | 1 000 000 | ≈ 1 мс |
| O(n log n) | ≈ 20 000 000 | ≈ 20 мс |
| O(n²) | 1 000 000 000 000 | ≈ 17 хвилин |
| O(2ⁿ) | 10³⁰⁰ ⁰⁰⁰ | довше, ніж існування Всесвіту |
Ця таблиця пояснює, чому вибір алгоритму критично важливий. Різниця між O(n log n) та O(n²) — це різниця між «20 мілісекунд» та «17 хвилин» на одному мільйоні елементів.
Best, Average, Worst case
Big O описує лише найгірший (worst case) сценарій. Але алгоритми мають ще два «обличчя»:
🟢 Best Case (Ω)
🟡 Average Case (Θ)
🔴 Worst Case (O)
Для сортування бульбашкою:
- Best case (вже відсортований масив): O(n) — одна перевірка, без обмінів
- Average case: O(n²)
- Worst case (масив відсортований у зворотному порядку): O(n²)
Сортування бульбашкою (Bubble Sort)
Ідея алгоритму
Назва — від аналогії з бульбашками повітря у воді: що легша (менша) бульбашка — то швидше вона «спливає» вгору. В масиві «важкі» (великі) елементи «тонуть» вниз (до кінця), а «легкі» (малі) — «спливають» вгору (до початку).
Принцип: порівнюємо два сусідніх елементи. Якщо лівий більший за правий — міняємо їх місцями. Повторюємо для всіх пар. За один прохід (pass) найбільший елемент гарантовано опиняється на своєму місці — в кінці масиву. Потім повторюємо для решти (без останнього елемента, він вже на місці).
Покрокове трасування
Для кращого розуміння, уявіть масив вертикально (індекс 0 — на самому верху, індекс N-1 — на самому дні). «Важкі» елементи (з більшими значеннями) будуть «тонути» вниз, а «легкі» (з меншими) — «спливати» вгору.
Масив: {5, 3, 8, 1, 2}
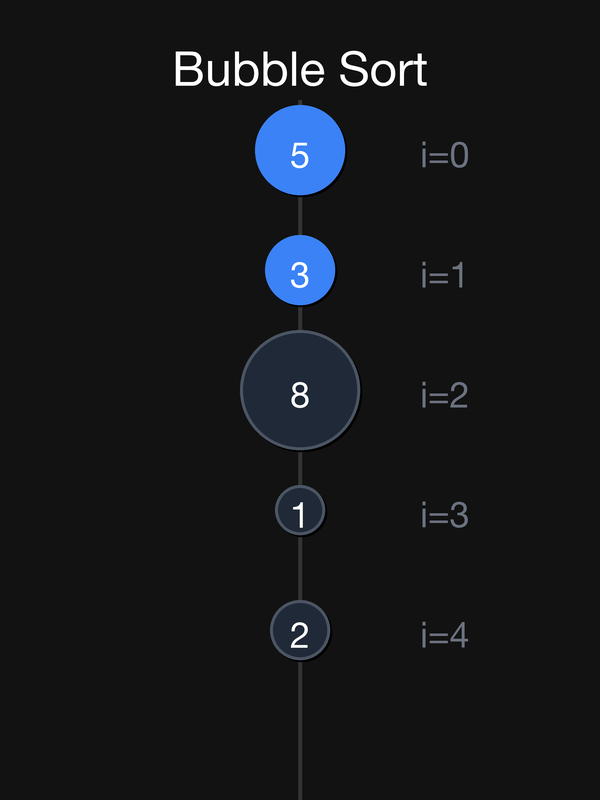
Прохід 1 (найважчий елемент тоне на саме дно):
| Крок | Дія | Масив |
|---|---|---|
| Початок | — | {5, 3, 8, 1, 2} |
| 0 vs 1: 5 > 3 → обмін | swap(5,3) | {3, 5, 8, 1, 2} |
| 1 vs 2: 5 < 8 → без обміну | — | {3, 5, 8, 1, 2} |
| 2 vs 3: 8 > 1 → обмін | swap(8,1) | {3, 5, 1, 8, 2} |
| 3 vs 4: 8 > 2 → обмін | swap(8,2) | {3, 5, 1, 2, **8**} |

8 зайняла своє місце на дні ✅
Прохід 2 (без останнього, який вже на дні):
| Крок | Дія | Масив |
|---|---|---|
| 0 vs 1: 3 < 5 → без обміну | — | {3, 5, 1, 2, 8} |
| 1 vs 2: 5 > 1 → обмін | swap(5,1) | {3, 1, 5, 2, 8} |
| 2 vs 3: 5 > 2 → обмін | swap(5,2) | {3, 1, 2, **5**, 8} |
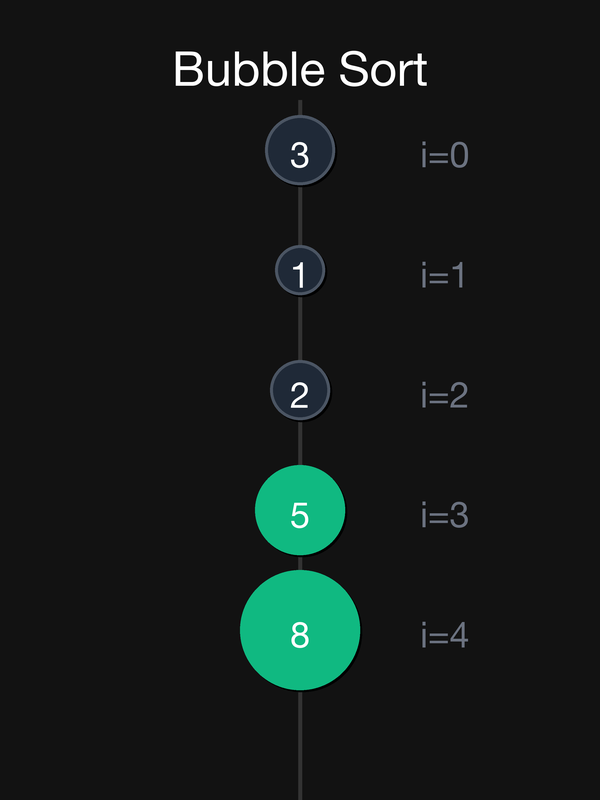
5 на місці ✅
Прохід 3:
| Крок | Дія | Масив |
|---|---|---|
| 0 vs 1: 3 > 1 → обмін | swap(3,1) | {1, 3, 2, 5, 8} |
| 1 vs 2: 3 > 2 → обмін | swap(3,2) | {1, 2, **3**, 5, 8} |
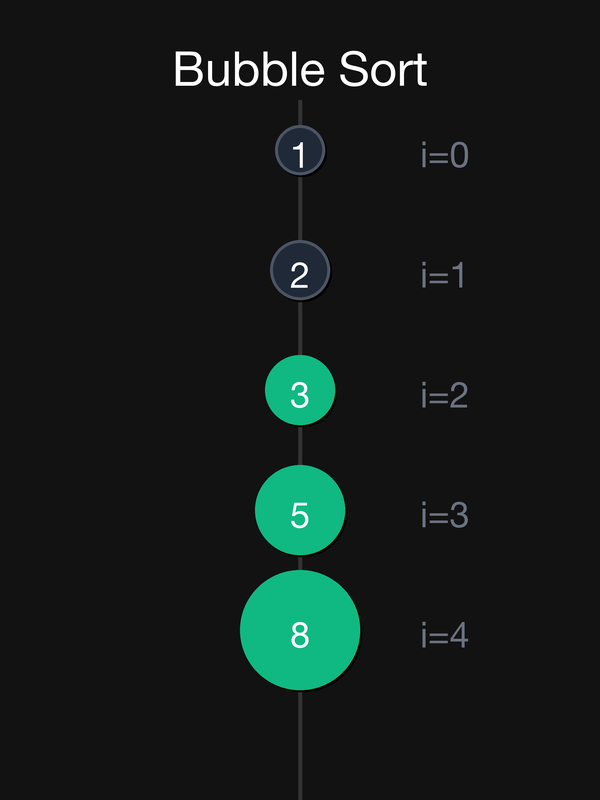
3 на місці ✅
Прохід 4:
| Крок | Дія | Масив |
|---|---|---|
| 0 vs 1: 1 < 2 → без обміну | — | {**1**, **2**, 3, 5, 8} |
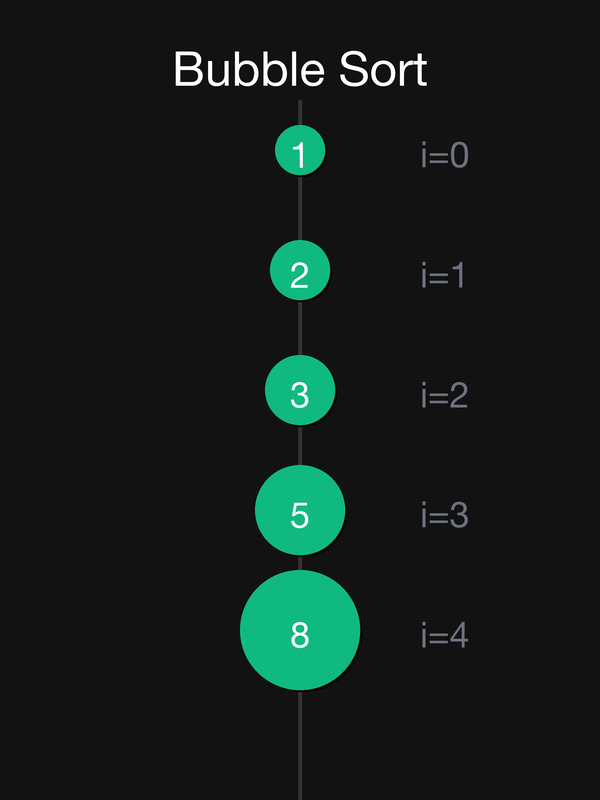
Масив відсортований ✅ {1, 2, 3, 5, 8}
Реалізація
#include <iostream>
using namespace std;
int main()
{
const int SIZE = 5;
int arr[SIZE] = {5, 3, 8, 1, 2};
// Зовнішній цикл: N-1 проходів
for (int pass = 0; pass < SIZE - 1; pass++)
{
bool swapped = false; // Прапор для оптимізації
// Внутрішній цикл: -pass, бо хвіст вже відсортований
for (int i = 0; i < SIZE - 1 - pass; i++)
{
if (arr[i] > arr[i + 1])
{
int temp = arr[i];
arr[i] = arr[i + 1];
arr[i + 1] = temp;
swapped = true;
}
}
// Якщо жодного обміну — масив вже відсортований!
if (!swapped)
{
break;
}
}
for (int i = 0; i < SIZE; i++)
{
cout << arr[i] << " ";
}
cout << "\n";
return 0;
}
State: After Pass 1
| Name | Type | Value |
|---|---|---|
| ◢arr | int[] | {3, 5, 1, 2, 8} |
| ◢swapped | bool | true |
Зверніть на оптимізацію з прапором swapped (рядки 13, 24, 28–31). Якщо за весь прохід жодного обміну не відбулося — масив вже відсортований, і ми виходимо достроково. Завдяки цьому best case стає O(n) замість O(n²): для вже відсортованого масиву потрібен лише один перевірочний прохід.
Аналіз складності
| Складність | |
|---|---|
| Best case | O(n) — один прохід без обмінів |
| Average case | O(n²) |
| Worst case | O(n²) — зворотньо відсортований масив |
| Пам'ять | O(1) — сортування на місці |
Коли використовувати: майже ніколи в продакшн-коді. Bubble sort — навчальний алгоритм. Єдиний реальний сценарій: перевірити, чи масив вже відсортований (з оптимізацією прапором).
Сортування вибіркою (Selection Sort)
Ідея алгоритму
Уявіть, що перед вами лежить купа іграшок різного розміру. Ви хочете розкласти їх від найменшої до найбільшої. Природний підхід: знаходите найменшу — кладете на перше місце. Потім знаходите найменшу з тих, що залишились — на друге місце. І так далі.
Принцип: ділимо масив на дві частини — «відсортовану» (ліворуч) та «невідсортовану» (праворуч). На кожному кроці знаходимо мінімальний елемент у невідсортованій частині та ставимо його на відповідне місце, міняючи з першим невідсортованим елементом.
Ключова відмінність від bubble sort: мінімум порядків обміну. В bubble sort обміни відбуваються часто. В selection sort — рівно N-1 обмін за весь алгоритм. Для ситуацій, де запис у пам'ять дорогий — це перевага.
Покрокове трасування
Найкращий спосіб уявити сортування вибіркою (Selection Sort) — це зобразити масив у вигляді стовпчиків і алгоритмічно розділити його на дві зони: відсортовану (зліва) та невідсортовану (справа). На кожному кроці алгоритм:
- Вибирає першу позицію у невідсортованій частині (обведена помаранчевим — це ціль, куди треба поставити мінімум).
- Шукає справжній мінімум серед усіх невідсортованих елементів (виділено синім).
- Міняє їх місцями. Бажаний елемент переходить у відсортовану зону (стає зеленим), а межа відсортованих даних зсувається вправо.
Масив: {5, 3, 8, 1, 2}
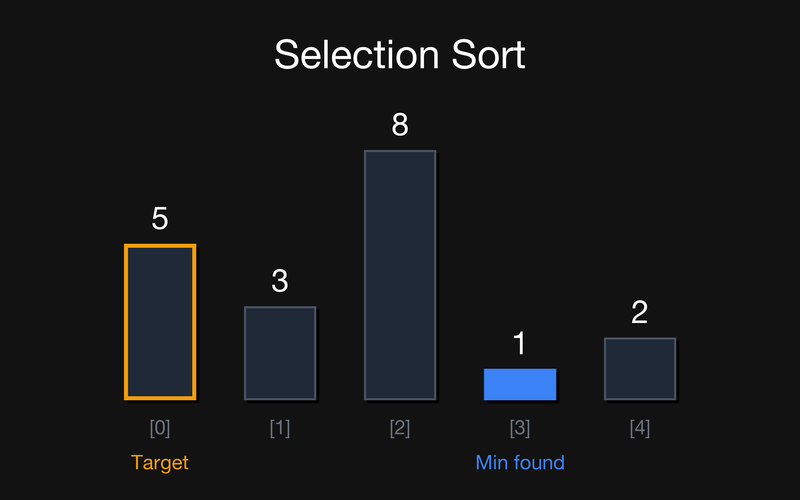
Крок 0: Шукаємо min у {5, 3, 8, 1, 2}. Найменший — 1 (індекс 3). Міняємо його з першим невідсортованим, тобто з позицією 0 (5).
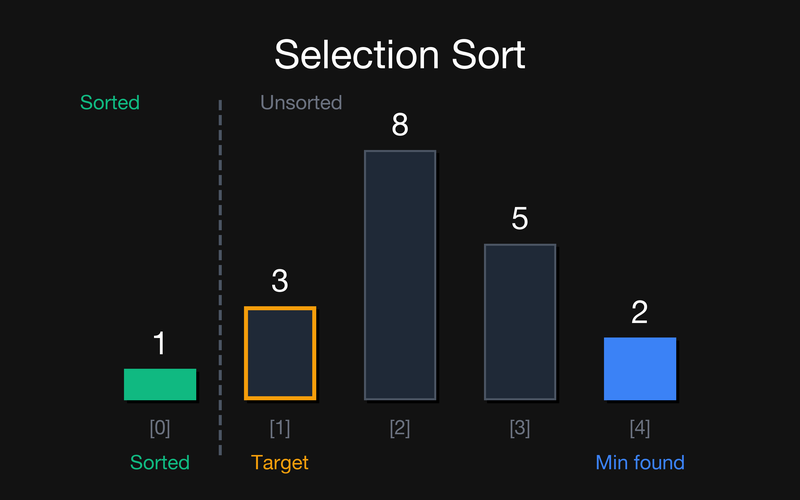
Крок 1: Відсортована частина вже має {1}. Шукаємо min серед невідсортованих {3, 8, 5, 2}. Це 2 (індекс 4). Міняємо його з позицією 1 (3).
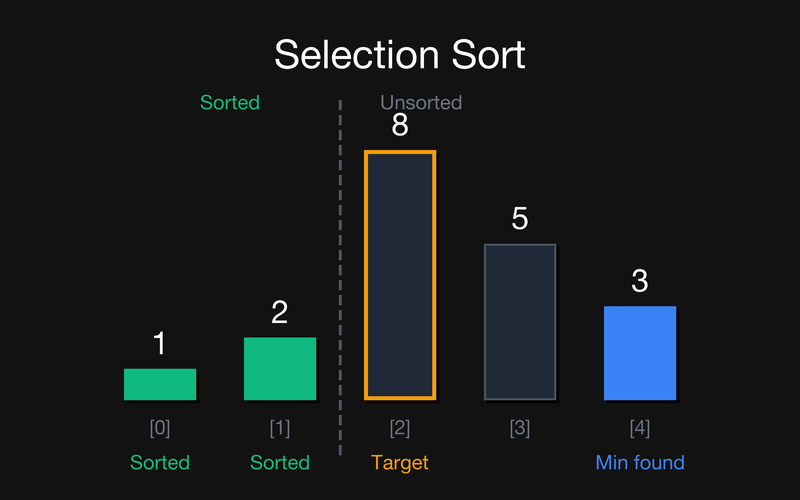
Крок 2: Відсортована частина {1, 2}. Шукаємо min у {8, 5, 3}. Це 3 (індекс 4). Міняємо його з позицією 2 (8).
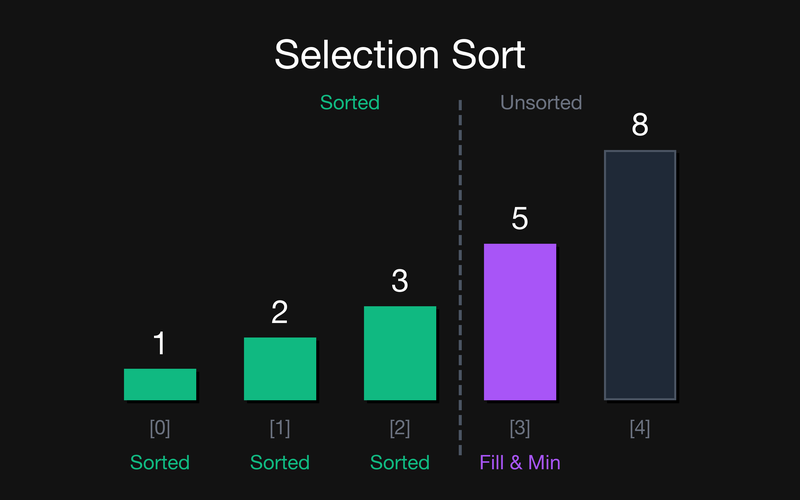
Крок 3: Відсортована частина {1, 2, 3}. Шукаємо min у {5, 8}. Це 5 (індекс 3). Воно вже стоїть на потрібному місці (збіг і цілі, і мінімуму), тому фізично залишається там само (виділено фіолетовим/подвійним обведенням у коді).
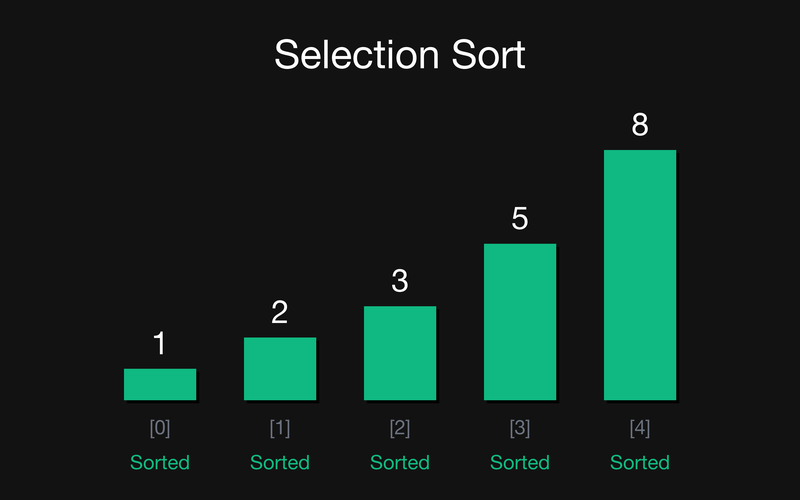
Всього обмінів: 4 (рівно N-1). Для порівняння — bubble sort на тому самому масиві зробив би значно більше.
Реалізація
#include <iostream>
using namespace std;
int main()
{
const int SIZE = 5;
int arr[SIZE] = {5, 3, 8, 1, 2};
for (int step = 0; step < SIZE - 1; step++)
{
// Знаходимо індекс мінімального елемента
// у невідсортованій частині [step .. SIZE-1]
int minIndex = step;
for (int i = step + 1; i < SIZE; i++)
{
if (arr[i] < arr[minIndex])
{
minIndex = i;
}
}
// Якщо мінімум — не вже поточний елемент, міняємо місцями
if (minIndex != step)
{
int temp = arr[step];
arr[step] = arr[minIndex];
arr[minIndex] = temp;
}
}
for (int i = 0; i < SIZE; i++)
{
cout << arr[i] << " ";
}
cout << "\n";
return 0;
}
Деталі реалізації:
- Рядок 14:
minIndex = step— спочатку вважаємо, що мінімум — перший невідсортований елемент. - Рядок 16: Внутрішній цикл починається з
step + 1— елементи доstepвже на своїх місцях. - Рядки 22–28: Перевірка
if (minIndex != step)перед обміном — якщо мінімум вже на правильному місці, обмін не потрібен.
Аналіз складності
| Складність | |
|---|---|
| Best case | O(n²) — пошук мінімуму відбувається завжди |
| Average case | O(n²) |
| Worst case | O(n²) |
| Кількість обмінів | O(n) — завжди не більше N-1 |
| Пам'ять | O(1) — сортування на місці |
Важлива особливість: на відміну від bubble sort, selection sort не виграє від вже відсортованих даних — він все одно виконує всі порівняння. Але через мінімальну кількість обмінів він може бути швидшим за bubble sort на масивах, де операція письма у пам'ять повільніша за читання.
Сортування вставками (Insertion Sort)
Ідея алгоритму
Уявіть, як ви тримаєте карти в руці під час карткової гри. Отримавши нову карту, ви вставляєте її на правильне місце серед вже відсортованих карт: знаходите позицію, де нова карта «менша за наступну» та «більша за попередню» — і вставляєте туди.
Принцип: поділяємо масив на «вже відсортовану» ліву частину та «ще не опрацьовану» праву. Беремо перший невідсортований елемент — поточний (key). Зсуваємо всі елементи відсортованої частини, що більші за нього, на одну позицію вправо — «звільняємо місце». Вставляємо поточний елемент на правильну позицію.
Insertion sort особливо ефективний на майже відсортованих даних: якщо масив майже правильний, елементи вставляються практично без зсувів.
Покрокове трасування
Як і раніше, масив можна умовно розділити на відсортовану та невідсортовану частини. Однак тут механіка інша:
- Масив починається з того, що перший елемент вважається вже відсортованим (розмір відсортованої зони = 1).
- Ми беремо перший елемент невідсортованої частини (називаємо його Key). На візуалізації ми його ніби «піднімаємо» в руку (виділено помаранчевим і зміщено вгору), залишаючи на його місці порожню комірку.
- Ми порівнюємо цей Key з усіма елементами відсортованої зони (рухаючись справа наліво). Якщо елемент більший за Key, ми зсуваємо його вправо. Потім вставляємо Key на звільнене місце.
Масив: {5, 3, 8, 1, 2}
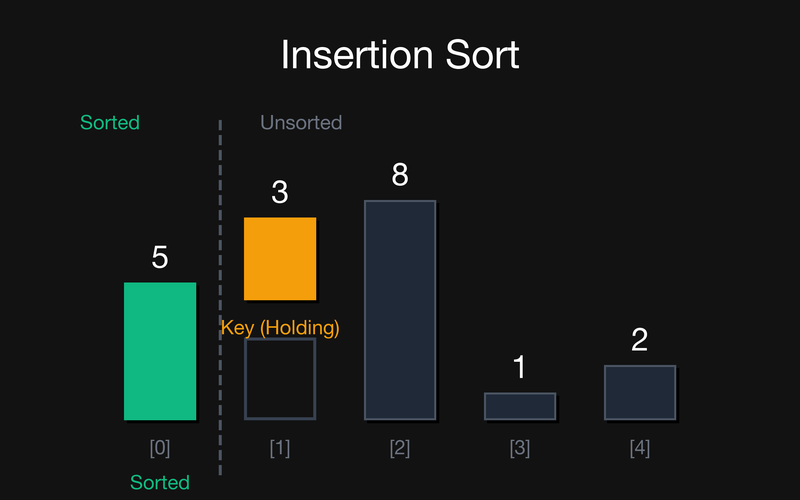
Крок 1: Відсортована частина {5}. Key = 3 (беремо arr[1]). Зсуваємо 5 вправо, бо $5 > 3$. Вставляємо Key на позицію 0.
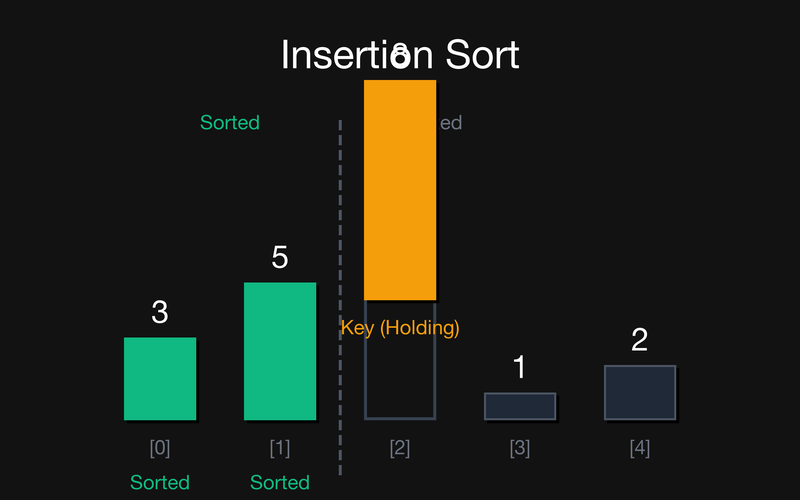
Крок 2: Відсортована частина {3, 5}. Key = 8 (беремо arr[2]). Оскільки $8 > 5$ (останній відсортований елемент), зсувати нічого не потрібно, просто ставимо 8 на своє ж місце.
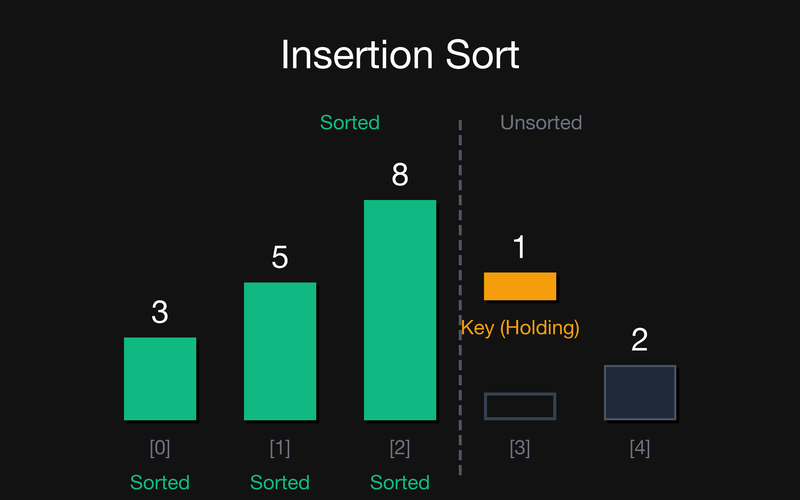
Крок 3: Відсортована частина {3, 5, 8}. Key = 1 (беремо arr[3]). Зсуваємо вправо 8, потім 5, потім 3. Вставляємо Key на звільнене місце 0.
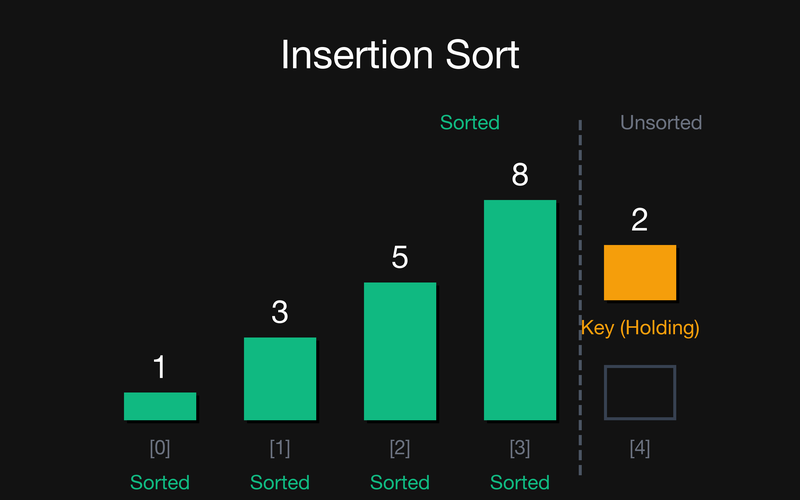
Крок 4: Відсортована частина {1, 3, 5, 8}. Key = 2 (беремо arr[4]). Зсуваємо 8, 5, 3. А от $2 > 1$, тому зупиняємось. Вставляємо Key на позицію 1.
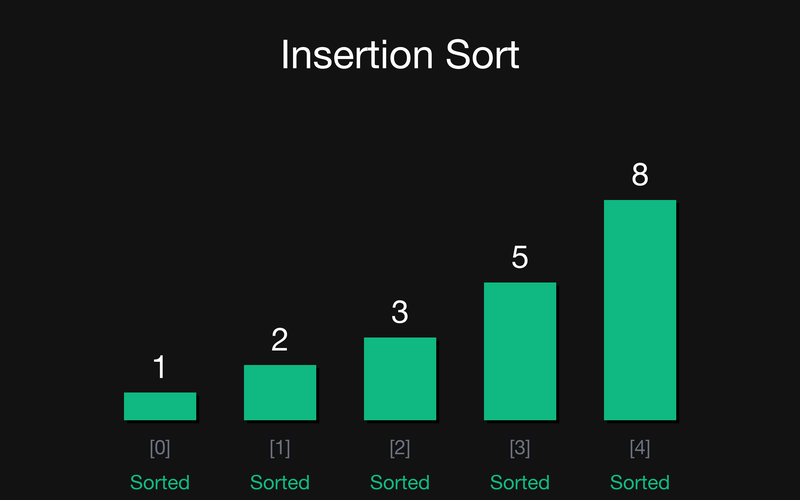
Фінал: Масив повністю відсортований. Всі елементи у правильному порядку.
Реалізація
#include <iostream>
using namespace std;
int main()
{
const int SIZE = 5;
int arr[SIZE] = {5, 3, 8, 1, 2};
for (int step = 1; step < SIZE; step++)
{
int key = arr[step]; // Поточний елемент для вставки
int j = step - 1; // Останній елемент відсортованої частини
// Зсуваємо вправо елементи, що більші за key
while (j >= 0 && arr[j] > key)
{
arr[j + 1] = arr[j]; // Зсуваємо на одну позицію вправо
j--;
}
// j+1 — правильна позиція для key
arr[j + 1] = key;
}
for (int i = 0; i < SIZE; i++)
{
cout << arr[i] << " ";
}
cout << "\n";
return 0;
}
Ключові рядки:
- Рядок 10: Зовнішній цикл починається з 1 (не з 0): масив з одного елемента вже «відсортований».
- Рядок 12:
key = arr[step]— зберігаємо копію поточного елемента, бо він буде перезаписаний при зсувах. - Рядок 16:
while (j >= 0 && arr[j] > key)— умови зупинки: або вийшли за початок масиву, або знайшли елемент менший за key. - Рядок 18:
arr[j + 1] = arr[j]— зсув без тимчасової змінної! Ми просто котимо елементи вправо, ніби котимо кулю по похилій поверхні. - Рядок 22:
arr[j + 1] = key—jпісля циклу вказує на перший елемент, що менший або рівний key. Тому key іде на позиціюj+1.
Аналіз складності
| Складність | |
|---|---|
| Best case | O(n) — масив вже відсортований, while не виконується |
| Average case | O(n²) |
| Worst case | O(n²) — зворотньо відсортований масив |
| Кількість обмінів | O(n²) у найгіршому, O(n) у найкращому |
| Пам'ять | O(1) — сортування на місці |
Де insertion sort виграє: на малих масивах (до 15–30 елементів) та на майже відсортованих даних insertion sort часто швидший за quicksort — через менші константні накладні витрати. Тому багато реальних бібліотечних реалізацій quicksort перемикаються на insertion sort для малих підмасивів.
Швидке сортування (Quick Sort)
Ідея алгоритму: «розділяй і володарюй»
Quicksort — один з найефективніших алгоритмів сортування загального призначення та центральний приклад стратегії «розділяй і володарюй» (divide and conquer). Ідея: замість того, щоб вирішувати одну велику задачу, ми розбиваємо її на менші підзадачі аж до тривіального випадку.
Принцип:
- Обираємо опорний елемент (pivot) — будь-який елемент масиву.
- Розбиваємо (partition) масив на дві частини: ліворуч — всі елементи, що менші або рівні pivot, праворуч — всі, що більші.
- Рекурсивно сортуємо ліву та праву частини.
- Базовий випадок рекурсії: підмасив з 0 або 1 елемента вже «відсортований».
sort(arr) розбиває масив на дві частини та викликає sort(ліва_частина) і sort(права_частина).Операція partition: серце алгоритму
Partition — найважливіша та найхитріша частина quicksort. Розберемо варіант Lomuto partition scheme — простіший для розуміння:
Масив: {3, 6, 8, 10, 1, 2, 1}
Pivot: arr[right] = 1 (останній елемент)
i = -1 (« межа меншого» — inicially перед масивом)
j = 0: arr[0]=3. 3 > 1 → нічого
j = 1: arr[1]=6. 6 > 1 → нічого
j = 2: arr[2]=8. 8 > 1 → нічого
j = 3: arr[3]=10. 10 > 1 → нічого
j = 4: arr[4]=1. 1 <= 1 → i++, swap(arr[0], arr[4])
{1, 6, 8, 10, 3, 2, 1}, i=0
j = 5: arr[5]=2. 2 > 1 → нічого
j = 6: (pivot, не входить у цикл)
Фінальний swap(arr[i+1], arr[right]): swap(arr[1], arr[6])
{1, 1, 8, 10, 3, 2, 6}
↑ pivot на своєму місці (індекс 1)
Після partition: всі елементи ліворуч від pivot ≤ pivot, праворуч — > pivot. Pivot на фінальній позиції.
Покрокове трасування quicksort
Для візуалізації ми виділяємо Активний підмасив (Active Sub-array), який зараз сортується, в синю рамку. Обираємо опорний елемент (Pivot) — він помаранчевий. Всі елементи, які знайшли свою остаточну позицію і більше не будуть рухатися, стають зеленими (Locked).
Масив: {5, 3, 8, 1, 2}, pivot = останній елемент.
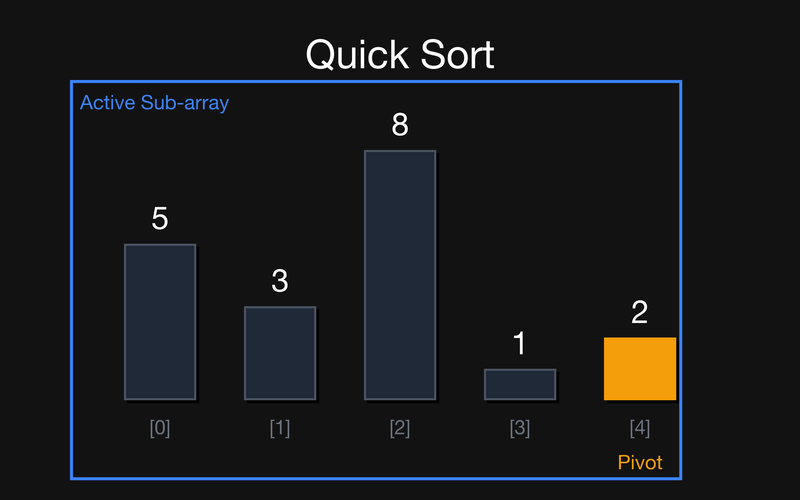
Крок 1: quickSort([5, 3, 8, 1, 2]). Активний весь масив. Обираємо останній елемент 2 як Pivot. Робимо partition (розбиття): всі менші або рівні 2 йдуть ліворуч, більші — праворуч.
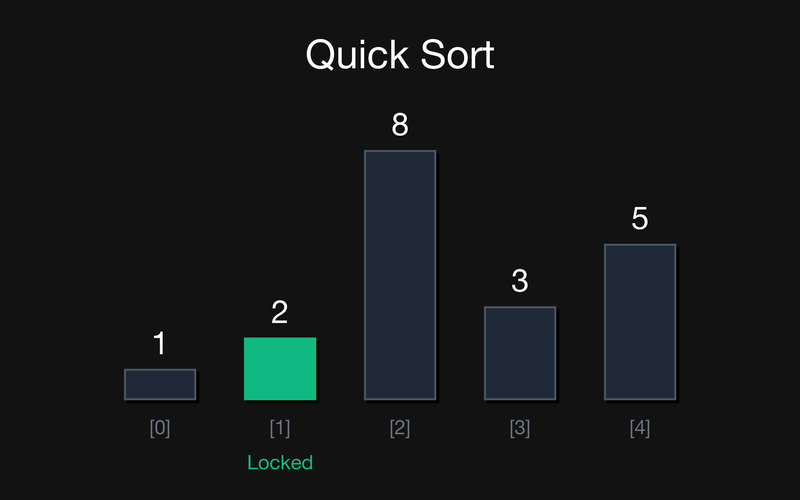
Крок 2: Результат першого розбиття — масив [1, 2, 8, 3, 5]. Pivot 2 став на своє остаточне місце (індекс 1, зелений колір). Тепер маємо два підмасиви: лівий [1] і правий [8, 3, 5]. Лівий має довжину 1, тому 1 автоматично зафіксовано.
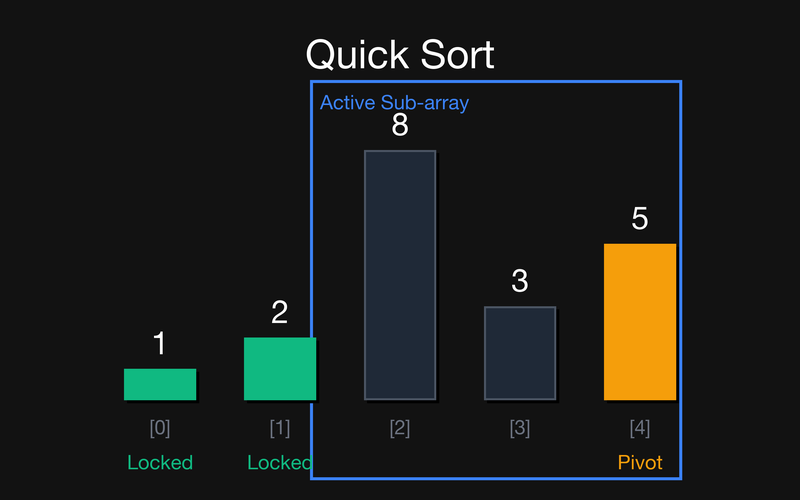
Крок 3: quickSort([8, 3, 5]). Активним стає правий підмасив. Pivot — останній елемент 5. Робимо partition.
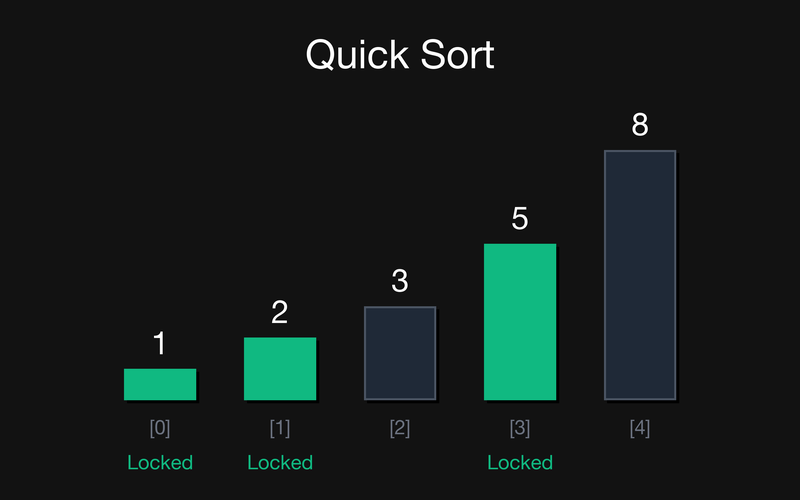
Крок 4: Після розбиття підмасиву маємо [3, 5, 8]. Pivot 5 став на своє остаточне місце. Зліва від нього утворився підмасив [3], а справа [8]. Оскільки їхня довжина 1, вони теж автоматично фіксуються.
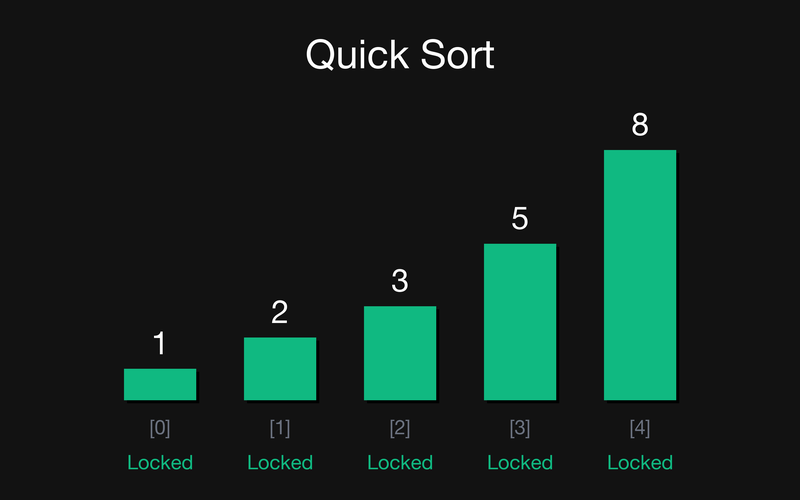
Фінал: Всі елементи масиву зафіксовані. Рекурсія завершена. Масив відсортовано [1, 2, 3, 5, 8].
Реалізація
#include <iostream>
using namespace std;
// Допоміжна функція: міняє два елементи місцями
void swap(int& a, int& b)
{
int temp = a;
a = b;
b = temp;
}
// Partition: розташовує pivot на правильній позиції,
// ліворуч — менші, праворуч — більші.
// Повертає індекс pivot.
int partition(int arr[], int low, int high)
{
int pivot = arr[high]; // Обираємо останній елемент як pivot
int i = low - 1; // i — індекс останнього "малого" елемента
for (int j = low; j < high; j++)
{
if (arr[j] <= pivot)
{
i++;
swap(arr[i], arr[j]);
}
}
// Ставимо pivot на своє місце
swap(arr[i + 1], arr[high]);
return i + 1; // Повертаємо індекс pivot
}
// Рекурсивне сортування підмасиву arr[low..high]
void quickSort(int arr[], int low, int high)
{
if (low < high) // Базовий випадок: 0 або 1 елемент — вже відсортовано
{
int pivotIndex = partition(arr, low, high);
// Рекурсивно сортуємо ліву та праву частини
quickSort(arr, low, pivotIndex - 1);
quickSort(arr, pivotIndex + 1, high);
}
}
int main()
{
const int SIZE = 7;
int arr[SIZE] = {10, 7, 8, 9, 1, 5, 3};
quickSort(arr, 0, SIZE - 1);
for (int i = 0; i < SIZE; i++)
{
cout << arr[i] << " ";
}
cout << "\n";
return 0;
}
Розберемо архітектуру:
swap(рядки 6–11): Допоміжна функція з параметрами-посиланнями (int& a). Посилання дозволяє змінити оригінальні значення, а не копії. Детально посилання розберемо у окремому розділі.partition(рядки 16–32): Схема Lomuto. Зміннаi— межа «малих» елементів. Якщо елемент менший за pivot (arr[j] <= pivot), збільшуємоiта ставимо його у зону малих.quickSort(рядки 35–45): Рекурсивна функція. Умоваif (low < high)— базовий випадок: підмасив із 0 або 1 елемента рекурсії не потребує.- Рядок 51:
quickSort(arr, 0, SIZE - 1)— запуск зі всім масивом.
Вибір pivot та його вплив
Вибір pivot може кардинально вплинути на ефективність:
Простий для реалізації. Проблема: якщо масив вже відсортований (або зворотньо) — кожен pivot вже на правильній позиції, але одна частина завжди порожня, а інша містить N-1 елементів. Виходить O(n²). Це найгірший випадок для Lomuto з останнім pivot.
{1, 2, 3, 4, 5}, pivot = 5
Розбивка: {} і {1, 2, 3, 4} — degenerujucha
pivot = arr[(low + high) / 2]. Для відсортованих масивів дає рівномірні половини. Стандартна рекомендація для навчальних реалізацій.arr[low], arr[mid], arr[high]. Статистично найкращий вибір для більшості реальних даних. Використовується у промислових бібліотеках (glibc, STL).Аналіз складності
| Складність | |
|---|---|
| Best case | O(n log n) — pivot завжди ділить масив навпіл |
| Average case | O(n log n) — у середньому розбивка досить рівна |
| Worst case | O(n²) — pivot завжди найменший або найбільший |
| Пам'ять | O(log n) — стек рекурсивних викликів |
Чому quicksort часто найшвидший на практиці (незважаючи на O(n²) у найгіршому випадку)?
- Кеш-дружній: quicksort працює з підмасивами послідовно, що відповідає принципу локальності у кеші процесора.
- Малі константи: порівняно з merge sort, quicksort не потребує додаткової пам'яті для злиття.
- Рідкісний worst case: при рандомізованому pivot або медіані трьох — O(n²) вкрай малоймовірний.
Порівняння алгоритмів
Зведена таблиця
| Алгоритм | Best | Average | Worst | Пам'ять | Стабільний? |
|---|---|---|---|---|---|
| Bubble Sort | O(n) | O(n²) | O(n²) | O(1) | ✅ Так |
| Selection Sort | O(n²) | O(n²) | O(n²) | O(1) | ❌ Ні |
| Insertion Sort | O(n) | O(n²) | O(n²) | O(1) | ✅ Так |
| Quick Sort | O(n log n) | O(n log n) | O(n²) | O(log n) | ❌ Ні |
5, стабільне сортування гарантує, що їх взаємний порядок не зміниться. Це важливо при сортуванні об'єктів за кількома ключами.Коли що обирати?
🫧 Bubble Sort
- Лише для навчання
- Перевірка «чи масив відсортований» (з оптимізацією прапором)
- Ніколи у продакшн-коді
🎯 Selection Sort
- Коли операцій запису у пам'ять має бути мінімум
- Маленькі масиви (до ~20 елементів)
- Коли потрібно точно знати, що буде не більше N обмінів
🃏 Insertion Sort
- Майже відсортовані масиви
- Маленькі масиви (до 15–30 елементів)
- Онлайн-сортування (елементи надходять по одному)
- Фінальна стадія у гібридних алгоритмах (Timsort, Introsort)
⚡ Quick Sort
- Загальний випадок: великі масиви довільних даних
- Коли важлива практична швидкість, а не теоретична гарантія
- З рандомізованим pivot — безпечно для більшості сценаріїв
- Основа STL
std::sort
Масштаб: як різниться час на практиці?
Для n = 10 000 елементів (орієнтовні значення):
| Алгоритм | Операцій (приблизно) |
|---|---|
| Insertion Sort (впорядкований вхід) | ≈ 10 000 |
| Quick Sort | ≈ 130 000 |
| Insertion Sort (випадковий вхід) | ≈ 25 000 000 |
| Bubble Sort | ≈ 50 000 000 |
| Selection Sort | ≈ 50 000 000 |
Навіть 10 000 елементів вже показують суттєву різницю між O(n log n) та O(n²).
Практичні завдання
Рівень 1 — Базовий
{4, 2, 7, 1, 5} вручну методом вибіркою (selection sort). Запишіть стан масиву після кожного кроку (всього 4 кроки). Потім перевірте своє рішення, запустивши програму і додавши вивід після кожного кроку.Доповніть реалізацію bubble sort лічильником обмінів. Для масиву {5, 1, 4, 2, 8} виведіть кількість обмінів на кожному проході та загальну кількість.
Pass 1: 3 swaps
Pass 2: 2 swaps
Pass 3: 1 swaps
Pass 4: 1 swaps
Total swaps: 7
Рівень 2 — Логічний
Модифікуйте insertion sort так, щоб він сортував масив за спаданням (від більшого до меншого). Змініть лише знак порівняння.
Перевірка: {5, 3, 8, 1, 2} → {8, 5, 3, 2, 1}
Визначте Big O складність кожного фрагменту. Обґрунтуйте відповідь:
// Фрагмент A
for (int i = 0; i < n; i++)
for (int j = i; j < n; j++)
sum += arr[i] + arr[j];
// Фрагмент B
int x = arr[n / 2];
// Фрагмент C
for (int i = 1; i < n; i *= 2)
cout << i;
// Фрагмент D
for (int i = 0; i < n; i++)
for (int j = 0; j < 10; j++)
arr[i] += j;
Рівень 3 — Творчий
Реалізуйте гібридний алгоритм: якщо розмір підмасиву ≤ 10 — використовуйте insertion sort, інакше — quicksort. Це наближує вас до реальних реалізацій стандартних бібліотек.
Порівняйте кількість операцій (через лічильник) між чистим quicksort та гібридом на масиві з 50 елементів.
Реалізуйте програму «Лідерборд» для гри. Зчитайте 5 пар (ім'я гравця, очки). Відсортуйте за очками за спаданням методом вибіркою (selection sort). Оскільки ім'я та очки — пов'язані дані, при кожному обміні очок міняйте також і відповідне ім'я.
Input:
Alice 850
Bob 1200
Carol 650
Dave 1100
Eve 900
Output:
1. Bob - 1200
2. Dave - 1100
3. Eve - 900
4. Alice - 850
5. Carol - 650
Підсумок
📌 Big O
📌 Bubble Sort O(n²)
📌 Selection Sort O(n²)
📌 Insertion Sort O(n²)
📌 Quick Sort O(n log n)
📌 Вибір алгоритму
Масиви
Одновимірні та двовимірні масиви в C++. Оголошення, ініціалізація, індексація. Обхід циклом. Алгоритми пошуку, сортування та накопичення. Рядки як масиви символів.
Алгоритми пошуку
Лінійний та бінарний пошук у масивах C++. Покрокові трасування, аналіз складності O(n) та O(log n). Передумови бінарного пошуку. Рекурсивна та ітеративна реалізації. Практичні задачі.